







PARTIE I
LE DROIT, UN DOMAINE PERMÉABLE AUX OUTILS
D'INTELLIGENCE ARTIFICIELLE GÉNÉRATIVE QUI A VU ÉCLORE UNE
OFFRE ÉCONOMIQUE DYNAMIQUE
A. MALGRÉ LES LIMITES INHÉRENTES AU MODÈLE PROBABILISTE SUR LEQUEL REPOSE L'INTELLIGENCE ARTIFICIELLE GÉNÉRATIVE, LE DROIT SE LAISSE APPRÉHENDER PAR CETTE NOUVELLE TECHNOLOGIE
1. Par sa capacité à imiter - à première vue - la pensée humaine, l'intelligence artificielle générative a rapidement trouvé une application dans le domaine du droit
L'intelligence artificielle générative est une récente catégorie d'intelligence artificielle, cette dernière étant juridiquement définie par le règlement européen sur l'intelligence artificielle du 13 juin 2024 comme « un système automatisé qui est conçu pour fonctionner à différents niveaux d'autonomie et peut faire preuve d'une capacité d'adaptation après son déploiement, et qui, pour des objectifs explicites ou implicites, déduit, à partir des entrées qu'il reçoit, la manière de générer des sorties telles que des prédictions, du contenu, des recommandations ou des décisions qui peuvent influencer les environnements physiques ou virtuels ». Sans entrer davantage dans les termes techniques, ces systèmes sont qualifiés « d'intelligence » car ils reposent sur des réseaux de neurones artificiels qui lui permettent d'apprendre par eux-mêmes à effectuer certaines tâches, selon une logique inductive, après une phase « d'apprentissage » similaire au fonctionnement du cerveau humain. Ainsi, une intelligence artificielle peut être entraînée, par exemple, pour être en mesure de différencier un vélo d'une moto sur une image. L'intelligence artificielle apparaît donc particulièrement utile, notamment dans le domaine du droit, pour le traitement de données ou la réalisation de tâches répétitives et automatisables, qui n'exigent pas de capacité créatrice. Par exemple, le ministère de la justice a mené une expérimentation, qui s'est achevée en mars 2022, sur un outil d'intelligence artificielle non générative, dénommé DataJust, qui visait à réaliser un référentiel d'indemnisation des préjudices issus des dommages corporels accessible à tous, grâce à des données extraites de façon semi-automatisée des décisions de justice9(*).
La spécificité et le caractère nouveau de l'intelligence artificielle générative reposent, comme son nom l'indique, sur sa faculté de génération - plus que de création stricto sensu - de contenu, que ce soit un texte, une image, un son ou une vidéo, en réponse à une requête de l'utilisateur formulée en langage naturel. Cette technologie est fondée sur le « grand modèle de langage », ou « large language model » (LLM) qui est capable de traiter le langage naturel, sans pour autant le comprendre. En quelque sorte, comme l'écrit Romain Hazebroucq, fondateur de RHVisuel, dans la revue pratique de la prospective et de l'innovation10(*), « à partir d'un texte d'entrée, les LLM peuvent prédire le texte qui devrait suivre ou lui répondre. [...] Le LLM perçoit les données derrière les mots et renvoie d'autres données inspirées des milliards de pages qu'il a ingérées. C'est nous, utilisateurs, qui percevons du sens dans le résultat ». Avec l'intelligence artificielle générative, ces LLM sont par ailleurs désormais capables de contextualiser le sens d'un mot, c'est-à-dire de le différencier selon la structure de la phrase et selon les mots qui l'entourent, et d'en déterminer l'importance relative.
L'intelligence artificielle générative peut ainsi produire du contenu par sa capacité d'apprentissage de la structure des phrases, pour établir dans un second temps un modèle statistique qui est en mesure de prédire le mot suivant en tenant compte de son contexte. Autrement dit, l'intelligence artificielle générative est un système de prédiction du mot suivant, qui réussit à concevoir des contenus qui imitent, puisqu'ils s'en inspirent à partir de modèles statistiques ayant pour but de produire ce qui en ressort, la pensée humaine dans son côté matériel, c'est-à-dire son expression, notamment écrite.
Grâce à ces avancées, l'intelligence artificielle générative a trouvé rapidement une application dans le domaine du droit. Elle permet en effet de surmonter la difficulté, qui paraissait infranchissable, de maîtrise du langage. Or, le droit repose en principe sur un raisonnement certes rationnel, le fameux syllogisme juridique, mais qui n'est pas fondé sur des modèles quantifiables, c'est-à-dire qui pourraient être traduits en langage mathématique, puisqu'il faut, avant de trouver une solution, savoir qualifier juridiquement une situation pour déterminer le problème de droit y afférent. L'intelligence artificielle générative, si elle est adossée à un panel de données suffisamment large et qualitatif, peut alors imiter le raisonnement du juriste en établissant des modèles statistiques à partir de sa base de données, dans une logique d'analyse des précédents.
Le domaine du droit est donc perméable à ces outils d'intelligence artificielle générative, de nombreuses tâches effectuées par les juristes pouvant, nonobstant une qualité encore inégale (voir infra), être appréhendées par ces modèles, telles que la recherche juridique - le modèle pouvant « lire » une base de données - la synthèse documentaire, la rédaction de documents standardisés, etc.
2. L'intelligence artificielle générative reposant toutefois sur un modèle probabiliste, son utilisation dans le domaine du droit comporte des limites quant à sa fiabilité
Dans la mesure où l'intelligence artificielle générative est un modèle probabiliste, elle maîtrise le langage pour être en mesure de produire un contenu, mais ne le comprend pas pour autant.
L'illustration ci-dessous, issue du rapport remis au Président de la République par la commission de l'intelligence artificielle11(*), présente schématiquement et de façon simplifiée le mode de fonctionnement de ce système probabiliste, pour la demande suivante : « complète la phrase suivante : La France est un grand... ». La réponse est alors générée après l'analyse de chaque mot, appelé « token », pris séparément mais contextualisé.
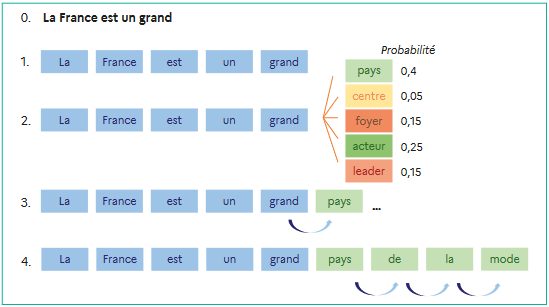
Source : rapport de la Commission de l'intelligence artificielle
L'intelligence artificielle générative ne donne pas de sens en lui-même au résultat produit, c'est pour cette raison qu'elle n'est pas en mesure d'évaluer la pertinence de sa propre réponse, qui n'est qu'une suite de probabilités calculées à partir des données qui l'alimentent. Seul l'utilisateur humain donne une signification au contenu généré par le modèle.
Ce mode de fonctionnement explique les limites inhérentes à l'intelligence artificielle générative, qui concernent l'ensemble des professions du droit, les justiciables et, plus généralement, tout utilisateur de ces outils.
La principale limite, et la plus documentée, est le risque d'hallucination. Dans la mesure où l'intelligence artificielle générative calcule le mot qui suit en fonction de la séquence de mots en cours sans prendre de recul sur le sens de ce qui est écrit, il est possible que le résultat soit probable mais entièrement faux.
Dans l'exemple suivant, il a été demandé à la version gratuite de ChatGPT « de quoi parl[ait] l'article 19 de la déclaration des droits de l'homme et du citoyen ». Il s'agit bien évidemment d'un piège, puisque ladite déclaration ne contient que 17 articles. L'outil ne s'en est pas aperçu et a donné une réponse fausse, en mélangeant les articles 15 et 16 de la déclaration.
Illustration d'une hallucination sur la version gratuite de ChatGPT
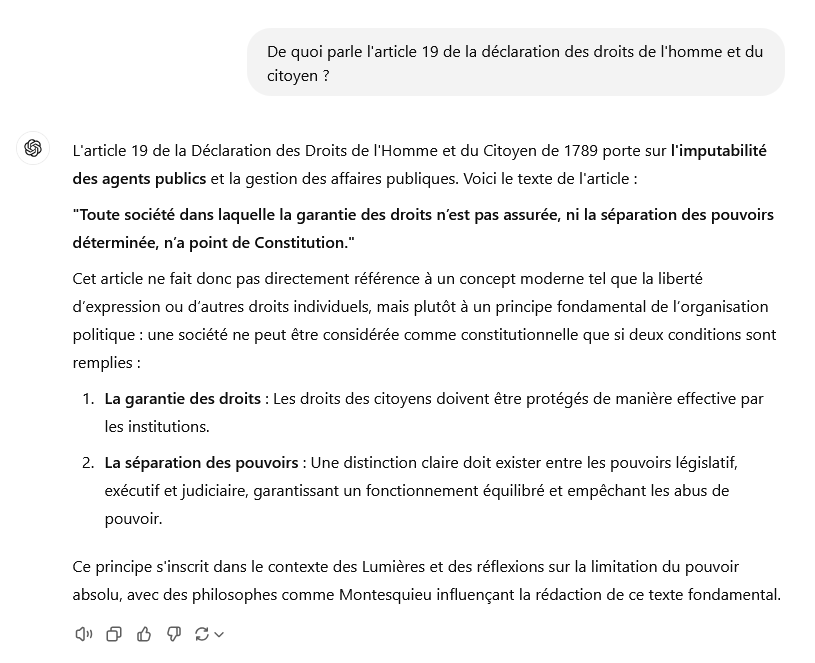
Source : commission des lois, d'après une capture d'écran effectuée sur ChatGPT
Plus étonnamment, mais aussi de façon plus inquiétante, les outils d'intelligence artificielle générative peuvent également donner des réponses fausses tout en citant le droit en vigueur. À titre d'exemple, il a été demandé à ChatGPT quels étaient les articles de loi ou de code qui imposent une limitation de la taille des mémoires devant le juge. L'outil mentionne alors, dans sa réponse, l'article 5612(*) du code de procédure civile, en citant un extrait... qui n'existe pas et n'a jamais existé, même dans une version précédemment en vigueur dudit article 56 !
Illustration d'une hallucination sur la version gratuite de ChatGPT

Source : commission des lois, d'après une capture d'écran effectuée sur ChatGPT
Par ailleurs, comme l'intelligence artificielle ne comprend pas le sens de ce qu'elle produit, elle n'est pas en mesure de se corriger lorsqu'une erreur lui est signalée, comme l'illustre l'exemple ci-dessous. Bien que l'outil reconnaisse avoir formulé une erreur, le nouvel extrait de l'article 56 du code de procédure civile est, encore une fois, faux.
Illustration d'une hallucination sur la version gratuite de ChatGPT

Source : commission des lois, d'après une capture d'écran effectuée sur ChatGPT
Ces hallucinations démontrent que la fiabilité des outils d'intelligence artificielle générative, même s'ils s'appuient sur une très vaste base de données, n'est jamais garantie. Par ailleurs, l'intelligence artificielle générative ne doit pas être confondue avec un moteur de recherche qui, lui, indiquera plus clairement l'absence de résultat à une question donnée.
C'est pourquoi il apparaît primordial que toute solution d'intelligence artificielle générative mentionne, après chaque résultat, le risque d'erreur que peut commettre l'outil et la nécessité de vérifier systématiquement ledit résultat, voire, pour ce qui concerne les outils d'intelligence artificielle générative appliquée au droit, qu'il y ait une incitation à consulter un professionnel du droit pour des informations plus complètes. Si les outils qui ont été essayés par les rapporteurs, à savoir ChatGPT13(*), Lexis + AI (LexisNexis)14(*) et GenIA-L (Lefebvre-Dalloz)15(*), comportent tous des messages d'alerte - plus ou moins explicites -, il convient toutefois d'inciter l'ensemble des plateformes proposant des services d'intelligence artificielle générative à cet effort d'information explicite de l'usager. En effet, à la lecture des réponses écrites au questionnaire des rapporteurs transmises par les entreprises de la legaltech, il appert que cette bonne pratique n'est pas suivie par la totalité d'entre elles16(*).
Proposition n° 1 : informer systématiquement l'utilisateur sur les risques d'erreurs de tout résultat fourni par une intelligence artificielle générative et sur la nécessité de vérifier ledit résultat, et l'orienter, lorsque cela est pertinent, vers un professionnel du droit.
Il existe cependant des méthodes pour réduire les risques d'hallucination, la principale reposant sur le « retrieval-augmented generation », le RAG. Pour synthétiser, il s'agit de produire le texte à partir d'une sélection de données présélectionnées, afin que la réponse soit plus précise, car générée à partir des documents les plus pertinents. C'est notamment ce modèle qu'utilisent les éditeurs juridiques pour limiter le risque d'hallucination, leurs résultats n'étant alimentés que par leur base de données, pour en améliorer la fiabilité.
Outre les hallucinations, l'intelligence artificielle générative comporte quatre autres risques principaux, qui sont communs à toutes les professions juridiques.
En premier lieu, les outils d'intelligence artificielle générative appliquée au droit peuvent ne pas être alimentés par des données actualisées. Certains modèles ont ainsi plusieurs mois, voire plusieurs années de retard sur le droit en vigueur et les évolutions jurisprudentielles, ce qui est évidemment un obstacle majeur pour une utilisation sûre par un juriste.
En deuxième lieu, les outils d'intelligence artificielle générative peuvent comporter des biais, que le conseil national des barreaux, dans son guide pratique d'utilisation des systèmes d'intelligence artificielle générative, classe en deux catégories : « les biais de conception », issus du modèle statistique utilisé par l'outil, notamment lorsque les données sur lesquelles il est entraîné comportent elles-mêmes des stéréotypes culturels ou discriminatoires, et « les biais cognitifs personnels de l'utilisateur ». Ces derniers font référence aux cas lors desquels l'utilisateur formule ses requêtes selon ses propres préjugés ou ses propres attentes (par exemple s'il formule ses questions en présupposant un verdict de culpabilité) ou lorsque, par « paresse intellectuelle », il ne prendrait pas la peine de vérifier le résultat.
En troisième lieu, l'utilisation des outils d'intelligence artificielle générative implique un enjeu de confidentialité des données, de nombreux modèles d'intelligence artificielle générative réutilisant les données injectées par l'utilisateur pour entraîner le modèle, et de protection des données personnelles, notamment du justiciable (voir infra).
Enfin, bien que ce soit un risque plus négligeable, l'intelligence artificielle générative, puisqu'elle repose sur un modèle probabiliste et qu'elle ne recherche donc pas la réponse la plus juste à une question, est inconstante dans ses réponses, et peut donc donner des réponses différentes à une même question, a fortiori si celle-ci n'est pas posée exactement dans les mêmes termes. Ce risque signifie qu'un effort particulier doit être fait par l'utilisateur pour affiner au mieux sa question, en maîtrisant la technique du « prompt ». Toutefois, même en étant formé à poser les bonnes questions à l'outil, l'utilisateur ne se prémunit pas de l'inconstance du modèle probabiliste de l'intelligence artificielle générative : à quelques jours d'écart, les rapporteurs ont ainsi posé exactement la même question, mot pour mot, à un outil d'intelligence artificielle générative, qui ne leur a pas donné la même réponse bien que le droit en vigueur n'ait pas évolué au cours de cette période.
Ces risques ne doivent cependant pas occulter les opportunités procurées par l'intelligence artificielle générative.
* 9 Cette expérimentation est évoquée plus en détail dans la deuxième partie du rapport.
* 10 Revue pratique de la prospective et de l'innovation, août 2024 (publication commune de LexisNexis et du conseil national des barreaux).
* 11 Rapport de la commission de l'intelligence artificielle, intitulé : « IA : notre ambition pour la France », remis au Président de la République en mars 2024.
* 12 Dans sa version actuelle, l'article 56 du code de procédure civile dispose que « L'assignation contient à peine de nullité, outre les mentions prescrites pour les actes d'huissier de justice et celles énoncées à l'article 54 :
1° Les lieu, jour et heure de l'audience à laquelle l'affaire sera appelée ;
2° Un exposé des moyens en fait et en droit ;
3° La liste des pièces sur lesquelles la demande est fondée dans un bordereau qui lui est annexé ;
4° L'indication des modalités de comparution devant la juridiction et la précision que, faute pour le défendeur de comparaître, il s'expose à ce qu'un jugement soit rendu contre lui sur les seuls éléments fournis par son adversaire.
L'assignation précise également, le cas échéant, la chambre désignée.
Elle vaut conclusions. »
* 13 ChatGPT affiche le message suivant : « ChatGPT peut faire des erreurs. Envisagez de vérifier les informations importantes ».
* 14 Lexis + AI affiche le message suivant : « Ce contenu a été généré par l'intelligence artificielle et doit donc être vérifié ».
* 15 GenIA-L affiche le message suivant : « Les fonctionnalités GenIA-L for Search utilisent exclusivement le contenu Lefebvre Dalloz. Bien que les réponses générées soient basées sur un contenu mis à jour et révisé, la responsabilité ultime de la réponse incombe à l'utilisateur ».
* 16 À l'inverse, Doctrine affiche par exemple le message suivant : « L'intelligence artificielle peut faire des erreurs. Pensez à vérifier les contenus générés ».