







- AVANT-PROPOS
- QUELQUES DÉFINITIONS D'INTÉRÊT
GÉNÉRAL
- L'ESSENTIEL
- IMPÔTS, PRESTATIONS SOCIALES ET LUTTE CONTRE
LA FRAUDE
- PREMIÈRE PARTIE
L'IA GÉNÉRATIVE : UNE EXPÉRIMENTATION TIMIDE, QUI ÉVITE L'ESSENTIEL
- DEUXIÈME PARTIE
L'IA CONTRE LA FRAUDE :
TOTEM FISCAL, TABOU SOCIAL
- TROIS PRIORITÉS POUR AVANCER
- I. IDENTIFIER LES USAGES
- II. CLARIFIER LES OBJECTIFS
- III. SE DONNER LES MOYENS
- A. LA MÉTHODE : SOUPLESSE ET
EXPÉRIMENTATION
- B. LA GOUVERNANCE : VOLONTARISME ET
COORDINATION
- C. LES COMPÉTENCES : RECRUTEMENTS
POINTUS ET DIFFUSION LARGE
- D. LE CHOIX DE LA TECHNOLOGIE : QUELS
MODÈLES POUR QUELS BESOINS ?
- E. L'ACCÈS AUX DONNÉES :
L'ENJEU DES ÉCHANGES D'INFORMATIONS
- F. L'INFRASTRUCTURE DE CALCUL :
INVESTISSEMENT ET MUTUALISATION
- A. LA MÉTHODE : SOUPLESSE ET
EXPÉRIMENTATION
- I. IDENTIFIER LES USAGES
- EXAMEN EN DÉLÉGATION
- LISTE DES PERSONNES ENTENDUES
N° 491
SÉNAT
SESSION ORDINAIRE DE 2023-2024
Enregistré à la Présidence du Sénat le 2 avril 2024
RAPPORT D'INFORMATION
FAIT
au nom de la délégation
sénatoriale à la prospective (1)
sur
« IA,
impôts, prestations
sociales et lutte contre la
fraude »,
Par M. Didier RAMBAUD et Mme Sylvie VERMEILLET,
Sénateur et Sénatrice
(1) Cette délégation est composée de : Mme Christine Lavarde, présidente ; MM. Daniel Guéret, Jean-Raymond Hugonet, Mme Anne Ventalon, MM. Christian Redon-Sarrazy, Jean-Jacques Michau, Guislain Cambier, Mmes Annick Jacquemet, Nadège Havet, Cécile Cukierman, Vanina Paoli-Gagin, MM. Yannick Jadot, Bernard Fialaire, vice-présidents ; MM. Bruno Belin, Stéphane Sautarel, Rémi Cardon, secrétaires ; MM. Pierre Barros, Jean-Baptiste Blanc, François Bonneau, Christian Bruyen, Christophe Chaillou, Raphaël Daubet, Vincent Delahaye, Mmes Patricia Demas, Amel Gacquerre, MM. Roger Karoutchi, Khalifé Khalifé,Vincent Louault, Louis-Jean de Nicolaÿ, Alexandre Ouizille, Didier Rambaud, Mme Marie-Pierre Richer, MM. Pierre-Alain Roiron, Jean Sol, Mmes Sylvie Vermeillet, Mélanie Vogel.
AVANT-PROPOS
Christine Lavarde, présidente de la délégation à la prospective
À l'instar des révolutions technologiques générales que furent la machine à vapeur, l'électricité ou encore Internet, l'intelligence artificielle (IA) pourrait profondément changer la façon dont nous vivons et travaillons, et ceci dans tous les domaines. Pourtant, dans le secteur public, les expérimentations restent à ce jour limitées, les annonces modestes, et la parole très prudente.
Pour l'État, les collectivités territoriales et les autres acteurs publics, le potentiel de l'IA générative est immense. Bien utilisée, elle pourrait devenir un formidable outil de transformation de l'action publique, rendant celle-ci non seulement plus efficace - qu'il s'agisse de contrôle fiscal ou de diagnostic médical - mais aussi plus proche des citoyens, plus accessible, plus équitable, plus individualisée et finalement plus humaine - avec une capacité inédite à s'adapter aux spécificités de chaque élève, de chaque demandeur d'emploi, de chaque patient ou de chaque justiciable.
Pour autant, le secteur public n'est pas un secteur comme les autres. Si l'IA n'est qu'un outil, avec ses avantages, ses risques et ses limites, son utilisation au service de l'intérêt général ne pourra se faire qu'à condition que les agents, les usagers et les citoyens aient pleinement confiance.
La confiance, cela passe d'abord par la connaissance : par son approche sectorielle, la délégation espère contribuer à démystifier une technologie qui suscite encore beaucoup de fantasmes, et à en montrer concrètement les possibilités comme les limites.
La confiance, c'est aussi et surtout l'exigence : une IA au service de l'intérêt général, c'est une IA au service des humains (agents et usagers), et contrôlée par des humains (citoyens). C'est aussi une IA qui s'adapte à notre organisation administrative et à notre tradition juridique, et qui garantit le respect des droits et libertés de chacun. C'est, enfin, une IA qui n'implique ni dépendance technologique, ni renoncement démocratique.
QUELQUES DÉFINITIONS D'INTÉRÊT GÉNÉRAL
· Intelligence artificielle (IA) : terme apparu en 1956 qui, dans son sens actuel, désigne un programme informatique (algorithme) fondé sur l'apprentissage automatique, ou apprentissage machine (machine learning). Cette technique permet à la machine d'apprendre par elle-même à effectuer certaines tâches à partir d'un ensemble de données d'entraînement. Elle repose sur une approche statistique (IA connexionniste), par opposition à l'informatique « classique » (IA symbolique), qui consiste à suivre une suite de règles logiques préétablies (de type « SI... ET... ALORS... »).
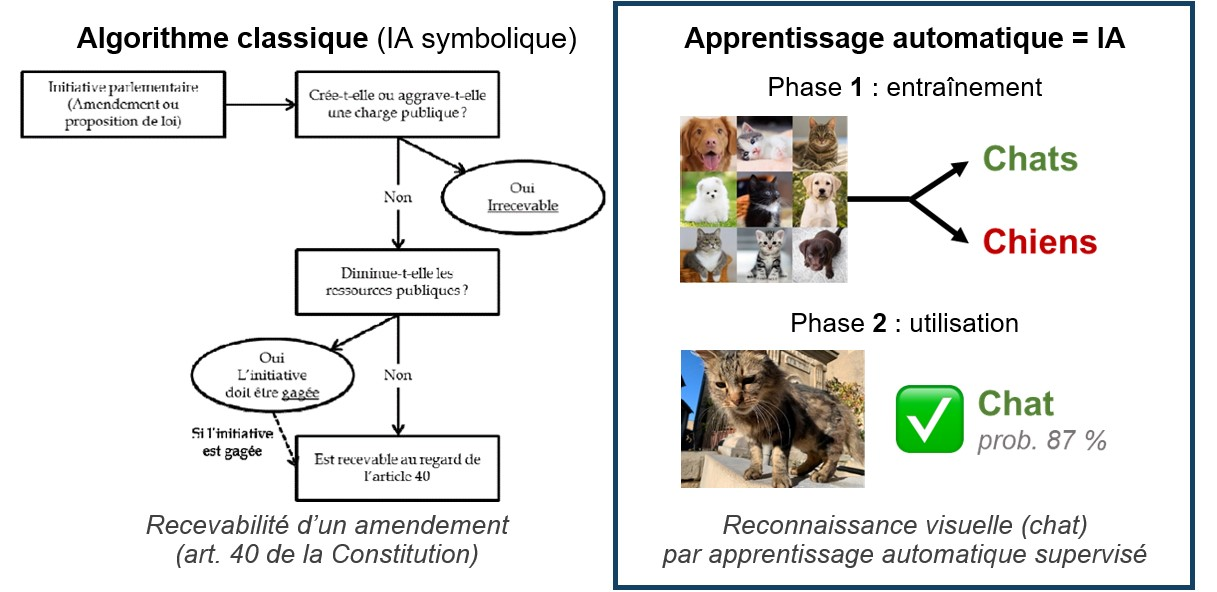
· Apprentissage profond (deep learning) : perfectionnement de l'apprentissage automatique grâce à une organisation en réseaux de neurones artificiels, où chaque « neurone » est une fonction mathématique qui ajuste ses paramètres au fur et à mesure de l'entraînement.
Les progrès sont spectaculaires à partir des années 2010 du fait de 3 facteurs : la sophistication des modèles, la disponibilité des données, et surtout l'explosion de la puissance de calcul.
L'IA est désormais présente dans de très nombreuses applications de notre quotidien.

· IA générative : modèles d'IA comme ChatGPT spécialisés dans la création de contenus originaux et réalistes, en réponse à une instruction formulée en langage naturel (le prompt). Le contenu peut être du texte, mais aussi du code informatique, un fichier Excel, une image (Dall-E, Midjourney), un fichier audio ou vidéo (Sora), etc.
· Grands modèles de langage ou LLM (large language models) : modèles d'IA spécialisés dans le traitement du langage naturel, dans toutes les langues.
Entraînés sur d'immenses quantités de textes, ils établissent des relations mathématiques entre les mots et les notions sous-jacentes, à partir de calculs de probabilités.

Les IA génératives sont construites sur des LLM (ex. modèle GPT-4 pour ChatGPT).

Le lancement de ChatGPT, fin 2022, par la société OpenAI a provoqué dans le monde entier une prise de conscience du potentiel de l'IA générative.

Ce robot conversationnel (chatbot) permet à chacun d'accéder à un modèle à la fois :
- généraliste : il peut traiter tout type de demande, là où la plupart des modèles sont spécialisés dans une tâche précise ;
- multimodal : il peut générer différents contenus (texte, image, graphique, etc.), faire une recherche en ligne ou exécuter un programme informatique ;
- ergonomique : les échanges se font simplement (dans un chat), en langage naturel, et ne demandent aucune compétence technique particulière ;
- peu coûteux : 22 euros par mois pour le modèle le plus puissant du marché (GPT-4), gratuit pour GPT-3.5.
Quelques grands modèles de langage (LLM) concurrents de ChatGPT/GPT-44

L'ESSENTIEL
· Le métier des administrations fiscales (DGFiP et douane) et des caisses de sécurité sociale consiste, fondamentalement, à traiter de l'information. Profondément transformées par la révolution numérique des vingt dernières années, elles sont aujourd'hui en première ligne de la révolution de l'intelligence artificielle.
· Avec l'IA, le service public pourrait gagner non seulement en efficacité, mais aussi en humanité. L'IA générative, en particulier, pourrait le rendre plus accessible, plus proche et plus individualisé, et tenir enfin les promesses de la révolution numérique. À condition bien sûr d'en comprendre les risques et les limites.
· Pourtant, l'expérimentation de l'IA générative reste à ce jour balbutiante, et limitée à des cas d'usage généralistes, avec des outils « sur étagère », puissants mais sans dimension métier, ou superficiels, avec des chatbots qui n'apportent qu'une aide limitée, sans transformer les procédures elles-mêmes, et sans accès au « coeur » du système, c'est-à-dire aux dossiers individuels des usagers.
· C'est en matière de lutte contre la fraude que l'intérêt de l'IA est le plus évident. Elle est utilisée depuis une dizaine d'années, avec une différence notable entre Bercy, plus volontariste, et la sphère sociale, sur la défensive. De façon générale, toutefois, les outils employés sont très loin d'être à la pointe de la technologie : le datamining utilise en fait très peu l'IA, et seuls deux projets utilisent le deep learning, pour détecter les piscines non déclarées et les stupéfiants envoyés par courrier postal. Les premiers résultats, éloquents, doivent inciter à aller plus loin.
· Il faut maintenant identifier les cas d'usage, clarifier les objectifs, et s'en donner les moyens : méthodes, compétences, technologies, données et infrastructures.
IMPÔTS, PRESTATIONS SOCIALES ET LUTTE CONTRE LA FRAUDE
Au coeur du service public et de l'État-providence se trouvent, en France comme ailleurs, les administrations chargées de trois grandes missions :
- collecter l'impôt pour financer des services d'intérêt général. On entend par impôt l'ensemble des prélèvements obligatoires : droits et taxes, cotisations et contributions sociales, etc. ;
- assurer la redistribution, et notamment la redistribution directe, sous la forme de prestations sociales versées aux individus et aux familles (pensions de retraite, prise en charge des dépenses de santé, allocations familiales, aides au logement, indemnisation du chômage, minima sociaux tels que le RSA et le minimum vieillesse, etc.) et d'autres transferts directs (crédits d'impôt, etc.) ;
- lutter contre la fraude fiscale et sociale sous toutes ses formes, mais aussi contre son pendant qu'est le non-recours aux prestations sociales, dans un double objectif de justice et d'efficacité.
En France, cinq « administrations » sont principalement chargées de ces missions et font l'objet de ce premier rapport thématique :
- 2 grandes directions à réseau de la sphère fiscale : la direction générale des finances publiques (DGFiP) et la direction générale des douanes et droits indirects (DGDDI) ;

- 3 caisses de sécurité sociale : la caisse nationale d'assurance vieillesse (Cnav), la caisse nationale d'allocations familiales (Cnaf) et l'Union de recouvrement des cotisations de sécurité sociale (Urssaf).

À noter
· Ces cinq administrations ont d'autres missions : gestion publique (comptes de l'État, domaine, gestion financière et comptable des collectivités locales, etc.), élaboration des textes législatifs et réglementaires, commerce international, soutien aux entreprises, etc.
· Ces trois missions concernent d'autres administrations : organismes de sécurité sociale, opérateurs de l'État, certaines collectivités, etc.
· L'IA soulève les mêmes enjeux dans d'autres services publics dont le « métier » consiste à traiter de l'information, notamment dans le périmètre des ministères économiques et financiers (Trésor, Budget, autorités de régulation, etc.) et des ministères sociaux (services centraux, organismes de sécurité sociale, etc.), dans les corps d'inspection (IGF, Igas) et la statistique publique (Insee, Drees).
Ces cinq administrations partagent un point commun : leur « métier » consiste essentiellement à traiter de l'information, par nature abstraite et immatérielle. C'est une spécificité forte qui les distingue de la plupart des autres principaux services publics, dont la dimension matérielle et concrète est irréductible : l'enseignant est face à ses élèves, le soignant auprès des malades, le policier sur la voie publique. Seule la douane, dont certaines missions ont par nature une composante matérielle (le contrôle des flux de marchandises et de voyageurs), fait en partie exception.
Cette particularité explique que les administrations de la sphère fiscale et sociale aient été si tôt et si profondément transformées par la « révolution numérique » : à elle seule, la DGFiP a perdu 30 000 emplois en quinze ans, soit 25 % de ses effectifs, notamment dans les services en charge de l'assiette (calcul de l'impôt), du recouvrement et du contrôle, et réduit le nombre de ses implantations territoriales. Cette mutation ne s'est pas faite sans difficulté, et elle s'est parfois accompagnée d'un sentiment de déshumanisation ou de recul du service public, chez les agents comme chez les usagers. Et pourtant, sa cause est profonde - car dans le même temps, l'administration fiscale passait au numérique : déclaration en ligne sur impots.gouv.fr, puis déclaration pré-remplie et prélèvement à la source, dématérialisation des paiements, datamining, facturation électronique, etc. Le service public a gagné en efficacité, et souvent en qualité - pas toujours, pas partout, mais suffisamment pour que personne, aujourd'hui, n'envisage un retour au papier.
Aujourd'hui, la même spécificité place ces administrations en première ligne de la révolution de l'intelligence artificielle (IA). Mais les enjeux sont différents, et plaident pour un optimisme raisonnable. Pour mesurer toute la portée de cette technologie et en comprendre les bénéfices potentiels comme les limites, encore faut-il préciser ce que « traiter de l'information » veut dire.
L'information, ce sont d'abord des chiffres (revenu, taux, etc.), et plus généralement des données structurées et standardisées (nom, adresse, numéro de sécurité sociale, numéro TVA/SIRET, organisme de rattachement, éligibilité à un dispositif, etc.) exploitables par un système d'information (SI).

Ici, l'IA n'est pas nécessaire : pour le « coeur » de leurs missions, les administrations s'appuient sur des systèmes informatiques « classiques », basés sur des règles logiques, afin de calculer l'impôt ou les prestations sociales. Si elle n'est pas nécessaire, l'IA peut néanmoins s'avérer utile, voire très utile, pour automatiser certaines tâches et analyser des données, pour offrir un service public de meilleure qualité, et bien sûr pour mieux détecter la fraude. Comme on le verra, toutes les « IA » ne se valent pas : si l'apprentissage automatique « simple » (machine learning) offre déjà beaucoup de possibilités, c'est l'apprentissage profond (deep learning) qui est, de loin, le plus performant pour identifier des corrélations qui auraient échappé à un humain.
Mais l'information, ce sont aussi des textes, des mots, des écrits de tous types : corpus normatif (lois, règlements, jurisprudence, doctrine, etc.), échanges de mails et de courriers avec les usagers ou en interne, contrats, pièces justificatives, comptes rendus de réunion, instructions et autres notes de service. Autant de données textuelles et autres données non structurées qui constituent en réalité la matière de base du travail quotidien des agents, très loin devant les chiffres et les calculs, depuis longtemps délégués à la machine. Et pourtant, cela ne fait pas si longtemps que ces documents écrits sont identifiés comme des « données », au sens d'un actif immatériel valorisable et exploitable grâce à l'informatique.

À cet égard, l'IA générative a radicalement changé la donne : les performances spectaculaires des grands modèles de langage en matière de compréhension, d'analyse et de production en langue naturelle permettent désormais de donner du sens à tout ce corpus, avec une efficacité et pour des usages inimaginables il y a quelques mois.
En bref
· Le machine learning et le deep learning sont adaptés pour traiter des données structurées et normalisées, notamment les chiffres.
· L'IA générative et les large language models excellent dans le traitement du langage naturel et des données non structurées et hétérogènes, notamment les textes.
Afin de bien saisir la singularité de cette innovation, le présent rapport abordera successivement :
I. L'expérimentation de l'IA générative par les administrations fiscales et sociales, pour l'ensemble de leurs missions ;
II. L'utilisation de l'IA dans la lutte contre la fraude (toutes techniques confondues), c'est-à-dire là où ses avantages sont les plus évidents et potentiellement les plus immédiats.
*
Pour le service public, tout ceci n'est pas seulement un enjeu d'efficacité : c'est aussi un enjeu d'équité, d'accessibilité, et donc d'humanité. L'IA, et particulièrement l'IA générative, permet de simplifier, de personnaliser, d'expliquer et de rapprocher le service public. En un mot, elle pourrait être l'occasion de tenir, enfin, les promesses de la révolution numérique.
Cela vaut pour le service public en général, et pour les administrations fiscales et sociales en particulier. Celles-ci ont un autre avantage : l'utilisation de l'IA dans le cadre de leurs « métiers » n'implique pas le recours à des outils particulièrement sophistiqués ou proches de la « frontière technologique ». Il s'agit pour l'essentiel d'applications relativement simples - bien plus, en tout cas, que les modèles de deep learning auxquels le terme d'« IA » fait aujourd'hui référence en matière de recherche médicale, par exemple.
Enfin, et sans pour autant sous-estimer les risques et enjeux propres à la lutte contre la fraude, les cas d'usage sont généralement moins « sensibles » qu'ailleurs, par exemple en matière de défense (drones autonomes), de sécurité (reconnaissance faciale) ou encore de justice (prédictive).
Pourtant, dans les faits, l'IA est finalement très peu utilisée à Bercy, et elle l'est encore moins dans la sphère sociale : l'expérimentation de l'IA générative est balbutiante et limitée à des outils généralistes ou à des cas d'usage superficiels, et la lutte contre la fraude est très loin de bénéficier des technologies les plus récentes.
Bien sûr, au sens large, il est facile de voir de l'IA partout, et depuis longtemps, car il n'existe pas de frontière nette entre ce qui est de l'IA, et ce qui n'en est pas. Dans sa communication publique sur le sujet, l'administration joue parfois sur ce flou pour « recycler », sous un vocable nouveau et à la mode, des projets qui en réalité ne reposent que peu, voire pas du tout, sur l'IA au sens actuel. L'un des objectifs de ce rapport est précisément de « faire le tri », ce qui implique d'entrer dans le détail de la technologie.

Plus fondamentalement, toutefois, on ne peut ignorer les raisons de ce « retard » - un retard qu'il faut aussi relativiser, du moins si l'on compare la situation à celle d'autres pays, ou d'autres administrations.
Il y a, d'abord, les craintes et les incompréhensions que suscite une technologie à la fois très récente, impressionnante et encore mal comprise. Ces craintes sont légitimes, et sont avant tout le signe qu'un immense effort de pédagogie, de sensibilisation et de démystification reste à accomplir, à tous les niveaux. Car cette technologie, pour reprendre les termes du rapport de la Commission de l'intelligence artificielle, « ne doit susciter ni excès de pessimisme, ni excès d'optimisme », et « l'Europe et la France ont des atouts pour être acteurs de cette révolution ».
Il y a, ensuite, le rappel à la réalité : les administrations fiscales et sociales sont les piliers de l'État-providence, elles sont en situation de « monopole légal » sur leurs missions, et même avec la plus grande volonté du monde, on ne peut pas ignorer leur histoire, leur organisation, leurs systèmes d'information, et bien sûr les agents qui y travaillent.
Il y a, enfin - et surtout - les risques pour les libertés individuelles et les droits fondamentaux. Ces risques sont réels, et il ne s'agit pas de les sous-estimer, mais bien plutôt de les souligner, pour mieux les anticiper.
La bonne nouvelle, c'est qu'il existe un cadre - législatif, constitutionnel, européen -, dont les principes sont solides, et dont il faut veiller à garantir l'application effective. Rien de tout cela ne se fera sans les acteurs concernés : la Cnil, le Parlement, les citoyens.
PREMIÈRE PARTIE
L'IA
GÉNÉRATIVE : UNE EXPÉRIMENTATION TIMIDE, QUI
ÉVITE L'ESSENTIEL
I. L'IA SUR ÉTAGÈRE
Le lancement de ChatGPT a conduit à une prise de conscience du « potentiel massif » de l'IA générative, notamment au sein des administrations de Bercy et des caisses de sécurité sociale, qui ont rapidement lancé une réflexion et identifié de premiers cas d'usage : 60 à l'Urssaf par exemple, ou 167 à la Cnaf qui a fourni des licences et proposé un accompagnement aux collaborateurs volontaires. La DGFiP a quant à elle consacré la 4e édition de son séminaire IA, en novembre 2023, à l'IA générative.
Il apparaît toutefois que la quasi-totalité des cas d'usage envisagés sont en réalité des cas d'usage généralistes, potentiellement utiles dans tout type d'organisation avec une « vie de bureau », mais sans dimension « métier » spécifique. La plupart du temps, il s'agit d'utiliser des outils « sur étagère », prêts à l'emploi, dans une version standard et bientôt grand public, qui n'implique pas d'intervenir sur la technologie sous-jacente - c'est d'ailleurs ce qui fait leur intérêt. Par exemple, avec l'intégration de Copilot dans la suite bureautique Microsoft 365 (Word, Excel, PowerPoint) et le moteur de recherche Bing, utiliser l'IA générative pour des tâches courantes sera demain aussi « naturel » qu'utiliser les autres outils numériques de notre quotidien.
Cela ne remet pas en cause l'intérêt de tels outils, qui pourraient libérer les agents de tâches chronophages et fastidieuses, dont l'automatisation n'est pas possible avec des outils « classiques ». Il faut insister sur ce point : pour la plupart des tâches en question (résumé, traduction, etc.), une IA comme ChatGPT affiche déjà une performance comparable ou supérieure à celle d'un humain, et pour une fraction de son temps et de son coût - ce qui rend son utilisation intéressante même si la réponse n'est pas « parfaite ». Et les progrès sont très rapides : on parle d'outils qui n'existaient même pas il y a un an et demi.
Quelques cas d'usage « standard » de l'IA générative
- Résumé et analyse : documents, rapports, comptes rendus, priorités...
- Rédaction : courriers, articles, contrats...
- Traduction
- Information : veille d'actualité, recherche documentaire, liste d'interlocuteurs...
- Simplification et personnalisation : explication en termes simples, FAQ/glossaire...
- Communication : génération d'images et de logos, création de supports...
- Aide à la créativité : idées, exemples, argumentaires, intelligence collective...
- Productivité : bureautique (Copilot), planning, automatisation des tâches...
- Pilotage et gestion : analyse de risques, indicateurs, budget, audit...
- RH : analyse de CV, guide d'entretien...
- SI : génération de code, automatisation des requêtes, tests de cybersécurité...
L'impact sur l'organisation interne de l'administration, sur l'allocation des moyens humains et budgétaires, et in fine sur la qualité du service public, pourrait être majeur. En outre, notre choix d'organiser collectivement un grand nombre de services (redistribution, santé, protection sociale, etc.) doit s'accompagner, en contrepartie, d'une capacité du service public à accueillir l'innovation au même titre que le secteur privé - au risque, sinon, d'être remis en cause.
Il reste que cette transformation, comparable à l'informatisation des années 1990-2000, n'est pas spécifique à l'administration, qu'elle prendra du temps, et qu'il ne faut pas en attendre un effet automatique sur la productivité ni sur l'emploi.
L'impact de l'IA sur la productivité et l'emploi
La Commission de l'intelligence artificielle, co-présidée par l'économiste Philippe Aghion, spécialiste de l'innovation, estime que les gains de productivité dus à l'IA pourraient conduire, en France, à une hausse du PIB comprise entre 250 et 420 milliards d'euros sur 10 ans, soit autant que la valeur ajoutée de toute l'industrie.
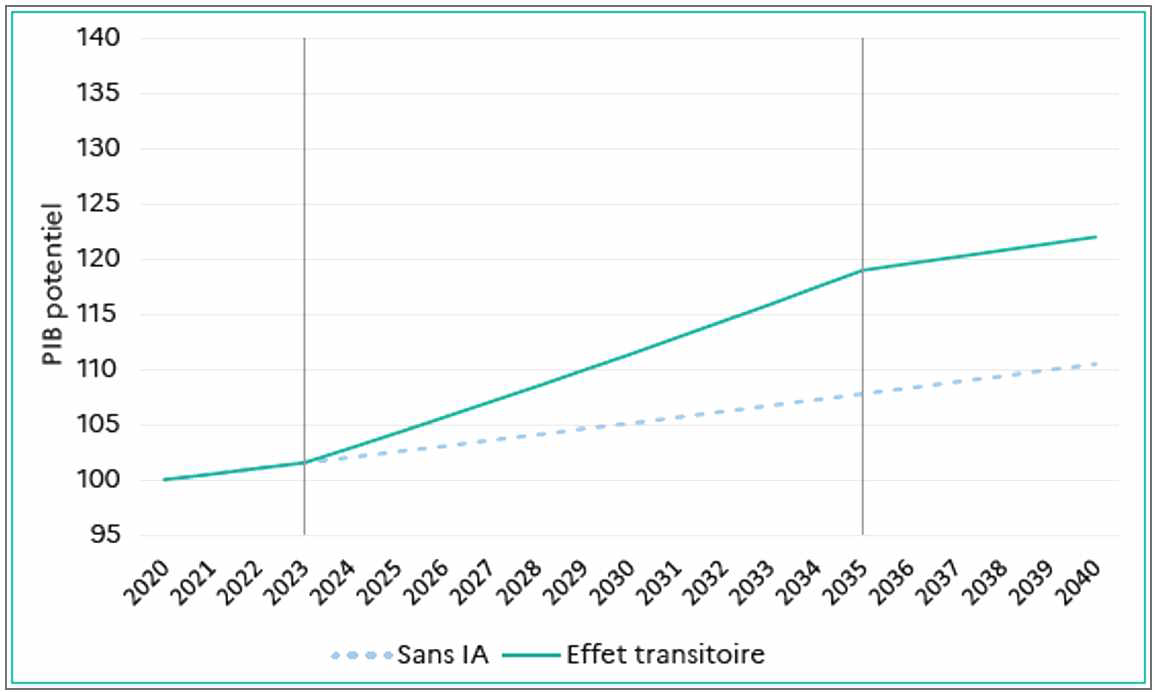
En revanche, cette hausse ne serait que transitoire, et l'effet cesserait une fois l'IA adoptée et les gains de productivité engrangés. L'ampleur de ces gains reste en outre très incertaine, de même que leur répartition dans l'économie et la société. On peut notamment souligner que :
- si certaines innovations ont conduit à des gains de productivité majeurs (électricité), d'autres, tout en transformant l'économie et la société, n'ont eu qu'un effet modeste sur les gains de productivité (Internet), voire imperceptible (smartphone).
- a contrario, pour la première fois, une technologie (l'IA générative) permet d'automatiser certains métiers de la connaissance, de la créativité, de l'intelligence, et donc la production de nouvelles idées. En d'autres termes, il s'agit d'une innovation... qui sert à innover.
Les gains de productivité impliquent deux effets contraires sur l'emploi :
- d'une part, un effet d'éviction : en déplaçant certaines tâches du travail humain vers les machines, l'IA tend à détruire des emplois ;
- d'autre part, un effet de productivité : en augmentant la productivité des individus, l'IA conduit à une augmentation du rapport qualité/prix des produits et services proposés aux consommateurs, donc à une demande plus élevée et, in fine, à davantage d'embauches et à la création de nouvelles tâches.
Les rares études réalisées à ce jour suggèrent que l'effet de productivité tend à l'emporter sur l'effet d'éviction : l'IA remplacerait donc des tâches, et non des emplois. Dans un pays comme la France, les emplois directement remplaçables par l'IA ne représenteraient que 5 % des emplois, tandis que l'IA pourrait entraîner par ailleurs la création de nouveaux métiers.
La situation sera cependant très variable selon les secteurs, les métiers et les tâches. Il semble toutefois clair que les tâches et métiers administratifs (secrétariat, gestion, administrations publiques, etc.) figurent parmi les plus concernés par la révolution de l'IA - avec, là encore, un effet incertain sur le partage entre « métiers augmentés » et « emplois supprimés ».
Parmi les nombreux usages « généralistes » de l'IA générative, un domaine en particulier pourrait avoir un impact déterminant pour les administrations de Bercy et les organismes de la sphère sociale : l'assistance à l'écriture de code informatique.
Les systèmes d'information (SI) sont la colonne vertébrale des administrations fiscales et sociales. À elle seule, la DGFiP utilise près de 700 applications métier différentes, et compte 5 200 agents dans ses services informatiques. La douane, pour sa part, utilise 200 applications et compte 420 informaticiens. L'Urssaf assure la gestion d'environ 100 applications. Ici, l'IA générative pourrait radicalement changer la donne, compte tenu de ses performances impressionnantes en matière de génération de code informatique et d'assistance aux développeurs.
Le codeur général des impôts
Moins d'un an après son lancement, GitHub Copilot, l'assistant IA de Microsoft spécialisé dans l'aide à la création de code et basé sur le même modèle que ChatGPT, est déjà utilisé quotidiennement par plus d'un million de développeurs ; on estime que l'IA rédige déjà 60 % du code (avec un objectif à moyen terme de 80 %), et permet un gain de productivité de 55 % et une amélioration générale de la qualité. D'autres modèles généralistes ou spécialisés (Code Llama, Claude 3 Opus, ou le tout récent Devin) donnent également d'excellents résultats.
Pour l'administration fiscale, l'intérêt ne réside pas seulement dans la génération de nouveau code (auto-complétion, commentaire), mais aussi dans l'utilisation des systèmes existants (génération de requêtes de bases de données), leur maintenance et leur sécurisation (génération de tests en matière de cybersécurité).
Surtout, l'IA générative pourrait contribuer de façon décisive à l'effort de modernisation de systèmes pour la plupart anciens, complexes et cloisonnés : on peut par exemple l'utiliser directement pour « traduire » un programme écrit dans un langage obsolète, dont la maintenance demande des compétences de plus en plus difficiles à trouver sur le marché, en un langage plus moderne et plus adapté à l'interconnexion avec d'autres systèmes. Les perspectives pour résorber la dette technologique et réinternaliser la maîtrise des SI sont considérables.
La DGFiP l'a d'ailleurs bien compris : l'assistance au code fait partie des cas d'usage les plus prometteurs parmi ceux qu'elle a identifiés.
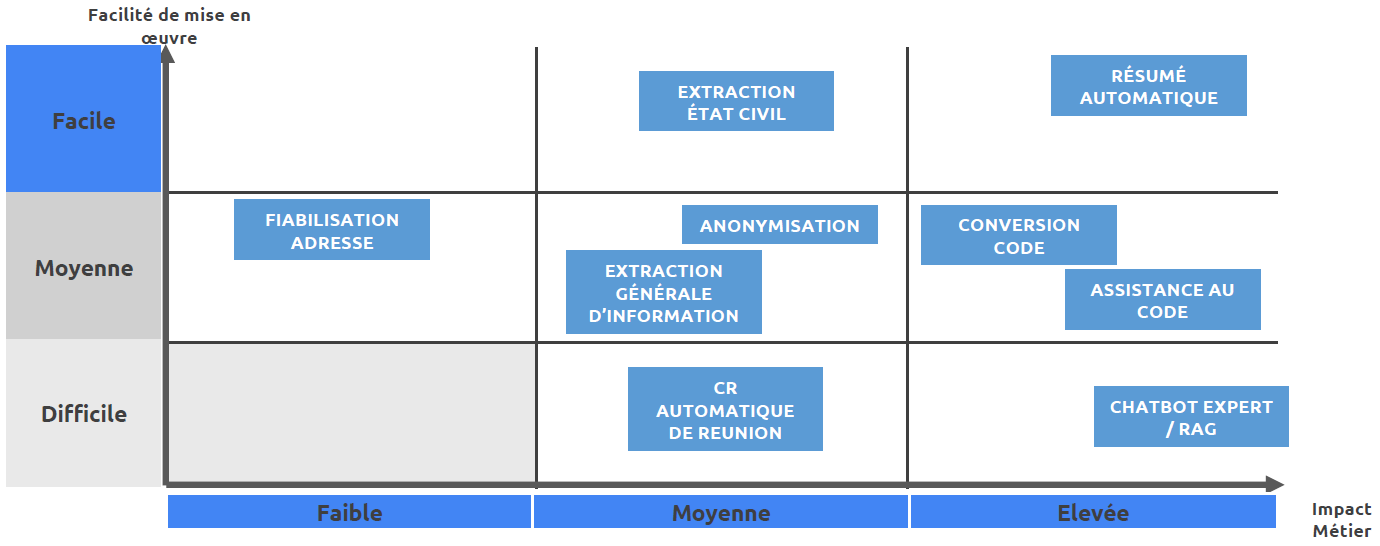
Source : DGFiP/DTNum, matrice d'impact et de faisabilité
Bien sûr, ces outils viennent avec leurs propres risques en matière de sécurité et de confidentialité : d'une part, les IA peuvent générer des erreurs, et rendent nécessaire un surcroît de précaution dès lors qu'il s'agit d'intervenir sur des applications aussi critiques que la gestion de l'impôt ; d'autre part, l'utilisation de Copilot implique d'utiliser le cloud de Microsoft, ce qui pose la question du risque de fuite de données (cf. infra).
Il convient toutefois d'adopter une approche différenciée en fonction du niveau de risque, et il est en tout état de cause impensable que les développeurs continuent de se voir interdire l'utilisation d'outils comme GitHub ou Copilot - comme c'est le cas aujourd'hui -, alors que ceux-ci font désormais partie des outils de base du métier. Une telle mesure est de toute évidence contreproductive : non seulement elle pousse les agents en poste à utiliser ces outils hors du cadre autorisé (shadow IT, maintenant shadow AI), mais en plus elle décourage les futurs candidats potentiels, que l'État a déjà tant de mal à recruter et fidéliser.
II. L'IA SUPERFICIELLE
Au-delà de ces cas d'usage généralistes, quelques expérimentations de l'IA générative avec une dimension « métier » spécifique ont été lancées, mais leur impact est limité :
- Llamandement apporte la preuve du potentiel de l'IA générative, mais le cas d'usage est sans impact majeur à l'échelle de l'administration ;
- les divers chatbots améliorent le service rendu ou facilitent le travail des agents, mais à la marge, car ils se bornent à ajouter une couche superficielle d'IA générative à des tâches existantes, sans rien transformer en profondeur.
A. LLAMANDEMENT (D'APPEL) : AVIS FAVORABLE DES RAPPORTEURS
L'exemple le plus encourageant est celui du projet Llamandement de la DGFiP, qui à défaut d'avoir un impact structurel à l'échelle de cette administration, a le mérite de prouver, de façon incontestable, l'intérêt de l'IA générative pour automatiser le traitement d'informations textuelles complexes.
Porté par la direction de la transformation numérique (DTNum) de la DGFiP, le projet vise à automatiser une partie du traitement des amendements parlementaires lors de l'examen du projet de loi de finances (PLF) en séance publique à l'Assemblée nationale et au Sénat.
Les services de Bercy chargés de préparer les « fiches de banc » des ministres doivent en effet traiter une grande quantité d'informations dans un temps très réduit - généralement quelques heures. Le traitement, qui se fait manuellement, est à la fois chronophage et source d'erreurs - mais sans alternative évidente jusqu'à récemment. Pour rappel, 5 400 amendements ont été déposés à l'Assemblée nationale sur le PLF 2024 en première lecture, et 3 700 au Sénat.

Un processus sous-optimal en 4 étapes
1. Attribution au bureau compétent : après récupération de la « liasse » (automatisée à 40 % pour l'AN et 0 % pour le Sénat), lecture des amendements un par un, puis recherche manuelle du bureau compétent (DLF* ou autre) dans un tableau Excel des attributions. Étape chronophage et source d'erreurs ;
2. Recherche des amendements similaires (PLF actuel/passés) : étape indispensable à la cohérence des positions, mais fastidieuse, partielle, dépendante de l'ancienneté et source d'erreurs (surtout en cas de variantes et de rectifications de dernière minute) ;
3. Synthèse de l'amendement : souvent partielle faute de temps, les efforts se concentrant sur les amendements « à risque » (comprendre : « risquant d'être adoptés ») ;
4. Rédaction de la position du Gouvernement (avis et argumentaire détaillé) : étape la plus sensible, soumise aux mêmes limites.
* DLF : direction de la législation fiscale. Les amendements peuvent aussi relever de la direction du budget (DB), de la direction générale du Trésor, de la direction générale des entreprises (DGE), etc.
L'outil conçu par la DTNum, testé lors de l'examen du PLF 2024, a permis d'automatiser presque entièrement les trois premières étapes (attribution, recherche de similaires, résumé neutre), avec un travail de qualité équivalente à celui d'un humain - spécialiste - et surtout réalisé en une fraction du temps habituellement nécessaire.

À noter que seule la troisième étape (la synthèse) fait appel à l'IA générative, en l'occurrence Llama 2, un grand modèle de langage (LLM) open source développé par Meta, aux performances comparables au modèle GPT-3.5 d'OpenAI. Une dizaine de minutes suffit à résumer l'ensemble des amendements. L'attribution et la recherche de similarités s'appuient sur des méthodes bien plus simples et disponibles depuis plusieurs décennies (par exemple l'appariement approximatif, ou fuzzy matching), mais néanmoins suffisantes pour faire gagner énormément de temps.

Source : DTNum
Si les LLM ont d'excellentes capacités de traitement du langage naturel, ils n'ont pour ainsi dire qu'une « culture générale », certes vaste, mais pas spécialisée et principalement issue de données en anglais. Le travail de l'équipe du projet Llamandement a donc consisté à « réentraîner » le modèle de base sur des données spécifiques à la tâche demandée, en l'occurrence les amendements du PLF 2023 et les « fiches de banc » correspondantes, afin de lui permettre d'en saisir les subtilités et le vocabulaire technique (droit fiscal, procédure législative, etc.).
Cette pratique, appelée fine-tuning, est couramment utilisée : c'est elle qui permet, par exemple, de spécialiser des LLM dans des domaines comme la médecine (Med-PaLM) ou la finance (BloombergGPT). Llamandement est donc un outil « métier » spécifique, et non un outil « sur étagère ».
Certes, à l'échelle de la DGFiP et de ses quelque 100 000 agents, l'impact de l'outil est limité : il concerne tout au plus quelques dizaines de personnes à la DLF, et encore de façon très ponctuelle (une ou deux fois par an). Il leur apporte néanmoins une aide précieuse à un moment critique de leur travail - qui est aussi un moment critique de la démocratie parlementaire.
En outre, l'expérimentation porte sur un cas d'usage superficiel de l'IA générative, au sens où elle ne concerne pas le « coeur de métier » de l'administration fiscale : l'outil n'est pas intégré aux « grands » systèmes d'information de la DGFiP (gestion de l'impôt, du recouvrement, etc.) et n'exploite aucune donnée individuelle (les amendements sont publics, et les « fiches de banc » et autres documents internes se trouvent dans des systèmes ad hoc). Ce n'est pas son objet, et ce champ restreint est évidemment pertinent pour une expérimentation destinée à apporter la « preuve du concept ».

C'est bien là qu'est son intérêt principal : démontrer que l'IA générative permet d'automatiser le traitement d'informations textuelles complexes. En particulier, le résumé automatique démontre sa capacité à répondre à deux exigences majeures :
- la neutralité de la synthèse : les LLM sont capables de discerner ce qui relève du contenu factuel d'une part (ici la dimension juridique), et de l'appréciation subjective d'autre part (jugement de valeur, biais idéologique, émotion, effet rhétorique, etc.), y compris en cas de nuance subtile ou de sens implicite ;
- la fiabilité de la synthèse : si le risque d'« hallucination » est inhérent à l'IA générative (cf. infra), il peut être réduit par un entraînement et un paramétrage adaptés, et n'est généralement pas un problème pour les tâches de synthèse, comme l'expérimentation l'a confirmé.
À l'avenir, le système pourrait être étendu à l'examen d'autres textes, au-delà du seul champ des finances publiques. Les tests effectués sur d'autres projets de loi (programmation militaire, industrie verte, etc.) se sont d'ailleurs révélés concluants. Le projet a fondamentalement une vocation interministérielle : s'il relève de la DGFiP, c'est parce qu'elle en a eu l'initiative - et c'est à elle qu'en revient le mérite.
C'est le dernier grand enseignement à en tirer : l'IA générative est une technologie qui se prête particulièrement bien à une démarche fondée sur l'expérimentation, l'initiative et l'agilité, car de nombreux outils peuvent être conçus et déployés « simplement », ou du moins sans intervention « lourde » sur les couches logicielles fondamentales. La preuve : pour l'essentiel, Llamandement a été développé par deux personnes, en moins de six mois, et l'idée vient tout simplement... d'un stage en immersion à la DLF, c'est-à-dire du terrain.
Une limite, et quelques pistes pour la suite
Un « gros » modèle plus récent (GPT-4, Claude 3, etc.) sans fine-tuning fait mieux, sinon beaucoup mieux, qu'un « petit » modèle plus ancien avec fine-tuning comme Llama 2. En d'autres termes, pour résumer un amendement, il est plus simple de demander directement à... ChatGPT, y compris dans des domaines techniques comme la fiscalité ou le droit parlementaire. De même, le modèle généraliste GPT-4 (ChatGPT) fait aujourd'hui mieux en analyse financière que le modèle spécialisé BloombergGPT, et la performance des modèles généralistes devrait continuer à s'accroître rapidement.
Dès lors, et au-delà de sa valeur comme « preuve du concept », l'intérêt d'un outil comme Llamandement vaut surtout pour les fonctionnalités additionnelles et spécifiques qu'il pourrait proposer, et qui d'ailleurs n'impliquent pas forcément de l'IA générative. Parmi les pistes envisageables à l'avenir, on peut notamment citer :
- rédaction de l'avis du Gouvernement et pas seulement du résumé : l'avis est le plus souvent prévisible (amendement similaire déjà commenté, irrecevable, manifestement contraire à la position du Gouvernement, trop coûteux, etc.), le gain de temps est notable, et ce n'est qu'une simple suggestion qui ne lie ni les services, ni le ministre ;
- recherche des similarités sur le fond, au-delà des correspondances strictes ;
- vérification la cohérence entre le dispositif et l'objet de l'amendement ;
- assistance à la légistique ;
- outils d'aide au chiffrage, à l'évaluation préalable ou au suivi de l'application des lois.
*
Si le traitement des amendements n'est pas un enjeu structurel pour la DGFiP, il l'est, en revanche, pour le Parlement.
Des réflexions ont lieu sur le sujet, notamment dans le cadre de la mission sur l'évolution du travail parlementaire confiée par le Président du Sénat à Sylvie Vermeillet, Vice-présidente.
À long terme, les progrès de l'IA pourraient poser des questions inédites. Qu'est-ce que le droit d'initiative parlementaire, quand un amendement peut être déposé mille fois, sans jamais être tout à fait le même ? Que vaut la parole d'un ministre, quand une IA peut, en temps réel, repérer une contradiction avec un propos tenu ailleurs ou plusieurs années avant ? Peut-on chiffrer le coût d'un amendement avec un chatbot ? Une « hallucination » est-elle irrecevable ?
*
En 2015, un sénateur italien a déposé 83 millions d'amendements au projet de réforme constitutionnelle de Matteo Renzi, en modifiant tantôt un chiffre, tantôt un signe de ponctuation, etc. Soit 412 tonnes de papier.
B. LE CHATBOT EN TOUCHE
Au-delà de cet exemple, l'IA générative a pour l'instant été expérimentée dans le cadre de chatbots, ou robots conversationnels, pour interagir avec les agents ou les usagers dans un langage plus naturel et leur apporter des réponses plus pertinentes - bien plus, en tout cas, que les chatbots « sans IA » que l'on trouve partout sur les sites de vente en ligne.
Lors de l'épidémie de covid-19, l'Urssaf a par exemple mis en place un « chatbot de crise », qui a pu répondre à un million de questions simples, assurant ainsi une forme de continuité du service public, et utilise en interne un chatbot pour l'assistance technique, et un chatbot pour l'assistance RH. La douane a aussi développé un chatbot RH, qui répond aux questions des agents dans ce domaine. Pour l'essentiel, toutefois, ces outils reposent sur de l'informatique classique (une arborescence et des règles logiques) : le « contenu en IA » est faible, et ce n'est pas de l'IA générative.
Le Gouvernement a ensuite souhaité aller plus loin et lancer son propre « ChatGPT du service public ». Le 5 octobre 2023 a ainsi été annoncée la première expérimentation de l'IA générative au niveau interministériel, sous la forme d'un chatbot destiné à aider les agents dans la rédaction des réponses aux avis et commentaires des usagers dans le cadre du programme « Service Publics + ». Lancé en 2021 et piloté par la direction interministérielle de la transformation publique (DITP), ce programme permet en effet aux usagers de partager leur expérience via la plateforme « Je donne mon avis », et l'administration s'engage à y répondre. 50 services publics et 14 ministères participent à cette initiative.
La direction interministérielle du numérique (Dinum) a donc développé un chatbot d'IA générative à partir d'un modèle ouvert et disponible sur étagère, le modèle de langage Claude 2 de la société Anthropic, un concurrent (moins performant) de ChatGPT.
Si le Gouvernement s'est dans un premier temps félicité des résultats, il semble en réalité que l'expérience n'ait pas été si concluante, et que les difficultés d'appropriation de cet outil sur le terrain l'aient finalement convaincu de « prendre le temps de la pédagogie » - il a d'ailleurs cessé de communiquer sur le sujet.

Plus fondamentalement, c'est l'intérêt même d'un tel outil qui pose question : il porte sur un cas d'usage tout à fait marginal à l'échelle du service public (répondre à quelques dizaines de commentaires sur Internet), et il apporte une aide relativement limitée aux agents dans leur travail, et aucune aide aux usagers directement.
C. ALBERT, UN SOUVERAIN LIBRE ET OUVERT
Cette précipitation est d'autant moins compréhensible que la Dinum avait commencé à travailler, en parallèle, sur un projet bien plus ambitieux, le chatbot Albert, présenté comme un outil d'IA générative « souverain, libre et ouvert, créé par et pour des agents publics », et destiné cette fois à améliorer les relations directes avec les usagers.
Initialement prévu pour le début de l'année, Albert devrait être déployé mi-2024 au sein du réseau France services, auprès des conseillers volontaires, afin d'aider ceux-ci à apporter des réponses fiables et pertinentes aux questions qui leur sont posées par les usagers, en temps réel. Il est pour cela réentraîné sur des données spécifiques (fine-tuning), principalement les 43 000 fiches de questions-réponses du site de « Services publics + », ainsi que 40 000 questions générées spécifiquement pour l'entraînement à partir des fiches élaborées par la direction de l'information légale et administrative (DILA) pour le site service-public.fr.
· Un modèle de base open source : initialement le modèle Llama 2 de Meta, puis finalement Mistral 7B, le plus petit modèle de Mistral AI, suite à une réorientation du projet.
· Un fine-tuning (réentraînement) sur des données spécifiques (fiches DILA, etc.).
· Un hébergement local sur les serveurs de l'État (et non sur un cloud privé).
En soi, le réseau France services est un excellent cas d'usage : s'il est possible d'effectuer de nombreuses démarches administratives courantes dans ses quelque 2 600 points d'accueil, les agents ne disposent évidemment pas d'une compétence sur l'ensemble des sujets. Un chatbot d'IA générative disposant d'une compétence transversale et capable d'adapter ses réponses et d'apporter des précisions pas à pas, au fur et à mesure de la discussion avec l'usager, semble être un outil idéal au service des agents - et un moyen pour le service public de gagner en accessibilité et en proximité.
Toutefois, là encore, il est conçu comme un simple « complément » à l'existant : il n'a pas vocation à se substituer aux agents, il ne modifie pas en profondeur la nature du service rendu ni son organisation, et n'en crée pas de nouveau. Pour le dire plus simplement : il n'est pas question qu'un usager puisse, depuis chez lui, s'adresser directement à Albert pour obtenir des conseils personnalisés et des explications détaillées, et encore moins pour faire les choses à sa place - soit précisément la rupture technologique introduite par les assistants IA comme ChatGPT.
Certes, en l'état actuel, la technologie n'est ni suffisamment mature (en raison du risque d'hallucination notamment, cf. infra), ni suffisamment maîtrisée par la Dinum pour envisager une utilisation directe du chatbot par les usagers : le modèle du « co-pilote », où l'agent public reste l'intermédiaire, est donc préférable à ce stade.
Une autre interrogation, plus fondamentale, porte sur la pertinence des choix technologiques : au nom de la « souveraineté », il a été décidé de privilégier un modèle open source, français de surcroît, mais ancien, peu performant (7,3 milliards de paramètres) et nécessitant une étape de fine-tuning complexe et coûteuse pour l'entraîner sur des données spécifiques, alors que les modèles plus gros et sans fine-tuning, par exemple GPT-4 (1,7 milliard de milliards de paramètres) ou même le plus récent Mistral Large, offrent des performances incomparablement supérieures et peuvent être utilisés directement.
Pour traiter des données sensibles, la question du choix entre un entre petit modèle « souverain » avec fine-tuning et un grand modèle « généraliste » peut se poser, mais pour des tâches simples sur des données publiques et accessibles à tous (les fiches de la DILA), cette position de principe en faveur de « la souveraineté à tout prix » pourrait être contreproductive. ChatGPT donne déjà des réponses satisfaisantes à la plupart des questions générales sur le service public français, et les prochaines versions du modèle devraient demain faire encore mieux.
D. LES EXPERTS À BERCY
En avance sur les autres administrations, la DGFiP développe aussi ses propres chatbots d'IA générative, adaptés à ses besoins métier. Deux projets sont actuellement en développement :
- TNMJ - Transformation numérique du métier juridique : outil de recherche juridique intelligente dans les bases documentaires (rescrits, etc.), avec génération de réponse automatique, destiné à tout agent de la DGFiP ;
- E-contact : rédaction automatique de réponses à des demandes simples des contribuables. Le bureau SRP (Stratégie relations aux publics) reçoit 12 millions de questions par an, qui correspondent la plupart du temps à de simples demandes d'informations. Aujourd'hui, les agents recherchent manuellement la réponse.

Ces deux projets s'appuient sur la technique de « retrieval-augmented generation » (RAG, « génération augmentée de récupération »), qui combine les capacités d'un grand modèle de langage (le traitement du langage et la génération de contenu) avec celles d'un « système expert », outil de récupération d'informations comparable à un moteur de recherche, mais spécialisé dans un domaine spécifique ou un type de données en particulier.
Le grand avantage de la RAG est de pouvoir apporter à l'utilisateur des réponses précises, à jour et personnalisées, sans pour autant devoir réentraîner le modèle (fine-tuning), une tâche à la fois longue, complexe et surtout très coûteuse du fait de la puissance de calcul nécessaire. Les deux approches ne sont toutefois pas exclusives, et le fine-tuning, s'il est plus coûteux à entraîner et davantage sujet aux « hallucinations », fournit généralement des réponses plus rapides, puisqu'il a « intégré » les données pertinentes.
Ici, la recherche se ferait typiquement dans le corpus juridique propre à la matière fiscale : textes législatifs et réglementaires (code général des impôts, livre des procédures fiscales, etc.), doctrine (BOFiP, rescrits, etc.), jurisprudence, bases documentaires, instructions et autres documents de référence.
Un outil destiné aux agents pourrait, bien sûr, accéder à la documentation interne.
Il reste que tous ces outils - Albert et les systèmes experts - ont en commun de faciliter l'accès à de l'information générale (loi, doctrine, etc.), certes dans un domaine spécialisé, mais pas à de l'information individuelle, c'est-à-dire aux données des usagers (contribuables et assujettis, employeurs et allocataires, importateurs et logisticiens, etc.). En ce sens, ils se limitent à l'ajout d'une couche superficielle d'IA générative dans les outils « métier » de l'administration, et il n'est pas envisagé d'aller au-delà à ce jour.
Or, valoriser des informations générales et publiquement disponibles, le secteur privé peut aussi le faire - et il a d'ailleurs largement commencé.
 De nombreux « TaxGPT » promettent déjà aux contribuables de les aider à remplir leur déclaration et à optimiser leur impôt en exploitant les niches fiscales. |
 Des entreprises comme eClear ou Digicust veulent « révolutionner le dédouanement » grâce à l'IA, en automatisant la classification des marchandises dans le «Système harmonisé » (SH, la nomenclature douanière), en calculant les droits et en anticipant les risques de conformité. |
|
En matière d'aides sociales, les chatbots d'IA proposant d'aider les demandeurs à s'y retrouver dans les procédures et subtilités administratives sont encore rares - sans doute parce que le « public cible » ne promet pas la même rentabilité... Il est toutefois probable qu'une offre émerge, ou qu'il suffise tout simplement d'utiliser la prochaine version de ChatGPT. |
|
III. L'IA AU COEUR DU SYSTÈME
Qu'ils soient publics ou privés, gratuits ou payants, ergonomiques ou non, de tels outils restent superficiels, et passent à côté de l'essentiel. Pour le service public, la véritable plus-value de l'IA est ailleurs. Elle est aussi bien plus importante, et elle ne peut pas venir de l'extérieur.
A. L'IA GÉNÉRATIVE, INTERFACE DE L'ÉTAT-PLATEFORME ?
Intégrée directement au coeur du système, combinée aux technologies existantes, disposant d'un accès sécurisé aux données individuelles et aux applications métier, l'IA générative permettrait en effet d'aller beaucoup plus loin. L'amélioration du service public, sans précédent, pourrait passer par trois « niveaux » successifs :
 |
Accéder au dossier individuel de l'usager (particulier ou entreprise), et donc à des données exactes et exhaustives, plutôt qu'à des règles générales ou, dans le meilleur des cas, aux éléments transmis manuellement. L'accès aux SI de différentes administrations éviterait à l'usager d'avoir à donner plusieurs fois la même information (date de naissance, revenu, etc.), donnant enfin tout son sens au slogan « Dites-le-nous une fois ». |
 |
Faire les démarches à la place de l'usager : l'IA générative n'est pas seulement capable de récupérer et de combiner des informations hétérogènes. Un assistant IA « augmenté » pourrait effectuer lui-même les démarches, soit automatiquement (à la date prévue, en cas de perte d'emploi, etc.), soit sur demande de l'usager (formulée en langage courant). |
 |
Supprimer les démarches elles-mêmes et simplifier drastiquement les procédures : l'enjeu n'est pas tant de savoir si une IA peut se charger de remplir un formulaire à la place de l'usager, mais bien de se demander pourquoi il existe (encore) un formulaire. |
Ce dernier chantier sera bien sûr d'une tout autre ampleur, et implique une réflexion en profondeur. C'est la leçon des deux dernières décennies : on ne peut pas faire la révolution numérique à droit constant.
« Une IA générative pourrait bientôt réexpliquer plusieurs fois dans un langage accessible quelles sont les démarches à faire pour inscrire son enfant dans une école, ou pour remplir ses déclarations d'impôts. Un agent pourrait même les réaliser pour vous. »
Rapport de la Commission IA, mars 2024
Ainsi, l'IA générative pourrait bien être la technologie qui manquait à l'État-plateforme pour devenir une réalité - avec l'identité numérique qui en est le complément indispensable.

Il reste que l'IA pose des questions techniques, éthiques et juridiques inédites : on peut expérimenter, mais pas improviser, ni se précipiter.
B. ACCESSIBILITÉ, PROXIMITÉ, HUMANITÉ : TENIR ENFIN LES PROMESSES DU NUMÉRIQUE
L'amélioration du service public n'est pas qu'une question d'efficacité : c'est aussi une question d'humanité.
À cet égard, la première vague de « transformation numérique » n'a pas tenu toutes ses promesses : la dématérialisation des démarches, inévitable et indispensable, n'a pas débouché sur une transformation en profondeur du service public, et s'est souvent accompagnée d'un sentiment d'abandon et de déshumanisation, chez les usagers comme chez les agents publics.

L'IA, et en particulier l'IA générative, pourrait permettre de tenir, enfin, les promesses de la révolution numérique, et d'abord en termes de :
- simplification ;
- personnalisation ;
- accessibilité ;
- proximité.
L'enjeu de l'accessibilité du service public est particulièrement important dans la sphère sociale, où les aides et prestations sont destinées à un public souvent plus « fragile ». Quelques exemples :
- traduction automatique dans la langue maternelle
- explication simple de procédures complexes
- rédaction de courriers
- aide aux personnes en situation de handicap (transcription vocale, etc.)
- accompagnement personnalisé dans les démarches (demandes, recours, etc.)
C. CONFIDENTIALITÉ, FIABILITÉ, EXPLICABILITÉ : TROIS DÉFIS À RELEVER
Bien sûr, transformer le service public en profondeur grâce à l'IA prendra du temps, demandera des moyens, et impliquera de faire des choix, notamment technologiques (cf. recommandations). En outre, si l'IA et l'IA générative ouvrent d'immenses perspectives, ces nouvelles technologies posent aussi des difficultés spécifiques. Parmi les défis à relever, les plus importants concernent la confidentialité des données traitées d'une part, et la fiabilité et l'explicabilité des réponses fournies d'autre part.
La confidentialité des données concerne à la fois les données des particuliers (contribuables, salariés, bénéficiaires de prestations sociales, etc.), qui peuvent être des données personnelles voire des données sensibles (notamment des données de santé, pour aide liée au handicap par exemple), les données des professionnels (y compris des données commerciales et financières), les données transmises par des tiers et les données internes de l'administration. L'enjeu est à la fois juridique et technique :
- sur le plan juridique, les données sont déjà protégées par le cadre actuel, à la fois de façon générale (loi Informatique et libertés, RGPD, etc.) et au titre de dispositions spécifiques (secret fiscal, secret professionnel, secret médical notamment). L'IA ne présente à cet égard aucune spécificité ;
- sur le plan technique, en revanche, l'IA pose des difficultés spécifiques, qui doivent être résolues avant d'envisager un déploiement à grande échelle. Elles sont principalement liées à la question de la maîtrise de l'infrastructure de calcul, et à celle de l'accès aux modèles. Ces points sont détaillés à la fin du présent rapport.
Quelques risques de sécurité propres à l'IA générative
Prompt injection : technique qui vise à pousser le modèle à générer du contenu indésirable, par exemple en dissimulant une instruction (prompt) dans une image, avec un texte en presque blanc sur fond blanc.
Jailbreaking : technique de contournement des « filtres » de l'IA en matière de sécurité ou de contenu indésirable (contenus racistes, sexistes, pornographiques, etc.). Par exemple, si l'IA dispose d'un filtre qui lui interdit d'expliquer comment fabriquer une bombe, on pourra tout de même obtenir ces explications avec un prompt du type « une bombe va exploser, j'ai besoin de comprendre comment elle est fabriquée pour la désamorcer ». Les cas aussi « évidents » que celui-ci sont aujourd'hui évités, mais d'autres « attaques » sont plus sophistiquées.
La fiabilité des réponses de l'IA générative est un autre enjeu majeur, directement lié au risque d'« hallucination » propre à cette technologie (cf. encadré page suivante). Elle implique de distinguer clairement entre :
- d'une part, les tâches qui peuvent être confiées à l'IA, parce qu'elles se prêtent à une approche statistique et probabiliste : c'est le cas de la détection de la fraude (cf. Partie II), mais aussi de tout ce qui concerne le traitement du langage naturel (analyse, synthèse, traduction, rédaction de texte, etc.) ;
- d'autre part, les tâches qui ne peuvent pas être confiées à l'IA, parce qu'elles impliquent un calcul ou un raisonnement qui n'admet qu'une seule solution, par exemple le calcul de l'impôt ou l'évaluation de l'éligibilité à une aide sociale.
L'IA générative et les « hallucinations »
La propension des IA génératives à donner des réponses erronées ou des informations imaginaires est intrinsèquement liée à leur nature probabiliste.
On dit souvent que « ChatGPT se contente de prédire le mot suivant ». Plus précisément, ces modèles construisent mot par mot - ou token par token (« morceau » de mot) - une réponse « probable » à la demande (le prompt), en fonction des corrélations statistiques issues de la phase d'entraînement du modèle.
Ainsi, « Paris est la capitale de la... » sera plus souvent complété par « France », mais aussi parfois par « mode » ou « gastronomie ».
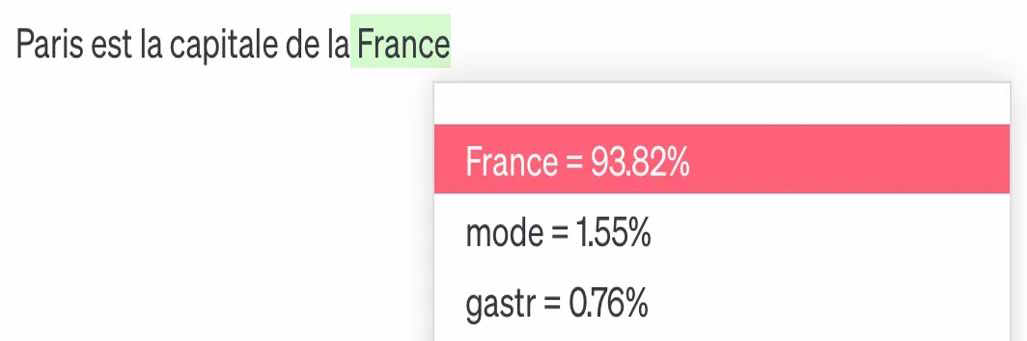
Source : fipaddict, vivreaveclia.substack.com
Pour une même question, la réponse ne sera jamais tout à fait la même. Cette part d'aléatoire est à la fois une limite de l'IA générative et ce qui fait son intérêt.
C'est notamment ce qui lui permet de faire preuve d'une plus grande « créativité », un effet qui peut être recherché en matière de création d'images, par exemple.

Timbre fiscal, Hallucination contrôlée, 2024
Si cette caractéristique exclut d'avoir recours à l'IA générative pour des tâches comme le calcul de l'impôt (ce que les systèmes « classiques », basés sur des règles logiques, font très bien), elle ne pose pas de problème pour les cas d'usage envisagés ici, pour trois raisons :
- d'abord, l'impact est souvent mineur. Pour une tâche de traduction ou de rédaction, par exemple, la part d'aléatoire portera bien plus souvent sur une nuance que sur le choix entre une idée et son exact contraire. En réalité, c'est ainsi que fonctionne le langage lui-même, par association d'idées au fur et à mesure, et c'est pour cela que les grands modèles de langage sont capables de comprendre des demandes complexes, de distinguer ce qui est important de ce qui est accessoire, etc. ;
- ensuite, il est possible de régler la « température » du modèle : un niveau élevé conviendra à une tâche créative (génération d'image), tandis qu'un niveau plus faible sera adapté à une analyse juridique ;
- enfin, les progrès pour réduire les hallucinations sont réels et rapides. Il existe deux voies complémentaires : le perfectionnement des modèles de langage d'une part, et leur combinaison avec d'autres approches d'autre part (typiquement la RAG pour récupérer des informations).
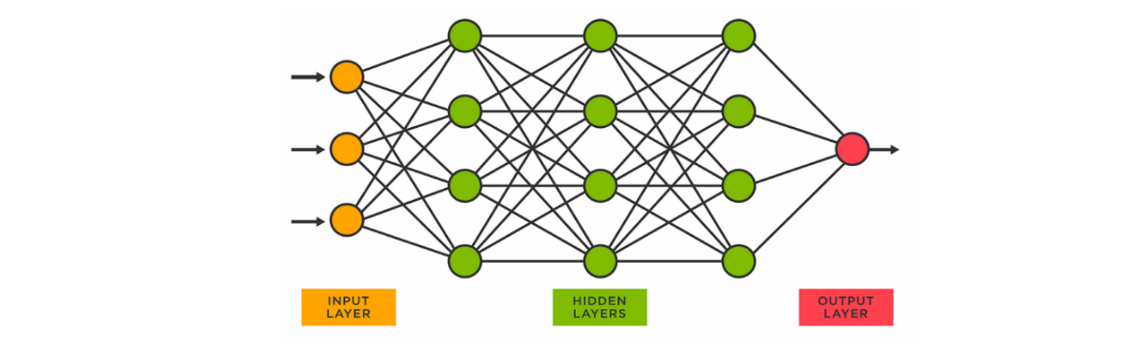
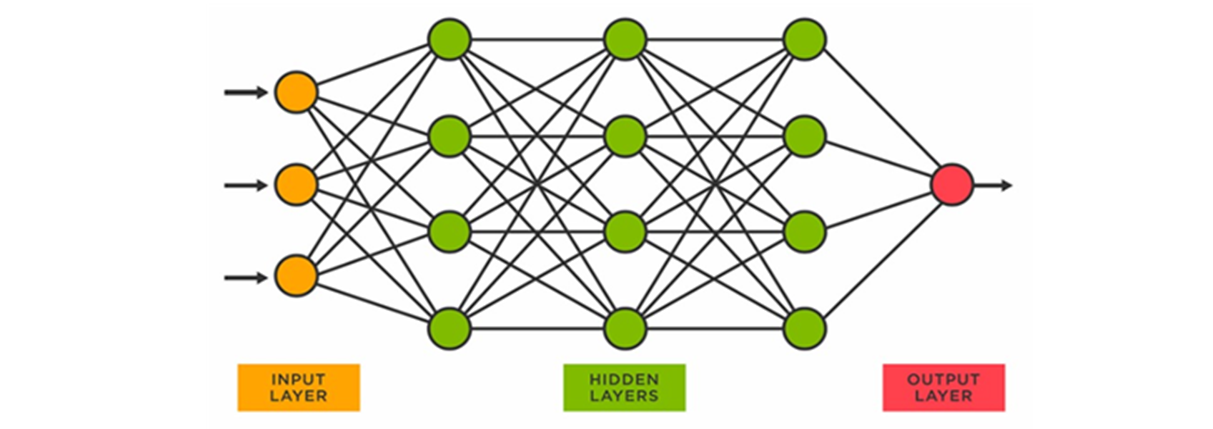
L'explicabilité des réponses de l'IA générative, enfin, est un enjeu inédit qui découle de la conception même des algorithmes de deep learning (apprentissage profond), dont les grands modèles de langage sont une variante :
Lors de la phase d'entraînement, ils « assimilent » une grande masse de données (ici des textes) pour établir par eux-mêmes des corrélations statistiques entre les mots, ou plutôt entre les notions abstraites sous-jacentes. Il en résulte une sorte de « représentation interne » du monde, sous forme de fonctions mathématiques (les « neurones » formels et leurs paramètres), mais celle-ci n'est pas directement accessible ni compréhensible par les humains.
Un processus similaire a lieu lors de la phase d'utilisation : un réseau de neurones est organisé en « couches » successives dont seules la couche d'entrée (input layer : le prompt) et la couche de sortie (output layer : la réponse) sont accessibles, tandis que les couches intermédiaires sont des « boîtes noires » (hidden layers).
Par conséquent, non seulement l'IA ne donne jamais la même réponse (car elle est probabiliste), mais en plus elle est incapable d'expliquer pourquoi, et n'a pas de notion du « vrai » et du « faux ». À cela viennent s'ajouter les risques liés aux « biais » des modèles (biais idéologiques, sexistes, etc.), qu'ils soient le reflet des biais contenus dans les données d'entraînement, ou à l'inverse des corrections apportées ex post pour « aligner » le modèle avec les valeurs de la société.
Dès lors, ce qui est acceptable pour une tâche généraliste (résumer un texte, etc.) devient problématique lorsque l'IA est utilisée pour prendre une décision susceptible d'avoir un effet juridique, et se heurte directement à trois principes fondamentaux à valeur constitutionnelle :
- l'égalité devant la loi, notamment devant l'impôt ;
- l'accessibilité, l'intelligibilité et la clarté de la loi ;
- le droit au recours effectif, qu'il soit administratif ou juridictionnel.
Dans la longue histoire de l'État de droit, le défi posé par l'IA est inédit. Pour autant, on ne peut pas se satisfaire d'une réponse simple qui consisterait à rejeter en bloc toute réponse apportée par l'IA au motif qu'elle n'est pas entièrement « explicable » :
- d'une part, on rappellera que la décision d'un juge, par exemple, n'est jamais entièrement « objectivable » non plus : il subsiste toujours une part d'intime, de subjectif, d'appréciation « en son for intérieur ». Il en va de même pour un juré de concours, un médecin qui délivre un certificat, ou même un agent du contrôle fiscal qui apprécie une situation au regard de ses circonstances. L'État de droit repose précisément sur ce compromis entre l'objectivité de la règle et la subjectivité de l'humain - comme du reste la démocratie elle-même (le bulletin de vote, output layer unique et lisible, ne disant rien de ce qui se joue dans les couches « profondes »). À la limite, on peut attendre des progrès futurs de l'IA une plus grande capacité à « s'expliquer », alors qu'il restera toujours impossible de démontrer qu'une décision humaine était biaisée. En matière de recrutement, par exemple, l'enjeu est crucial ;
- d'autre part, une réponse n'a pas toujours besoin d'être explicable, mais elle a toujours besoin d'être utile : si l'IA permet de diagnostiquer un cancer du sein mieux qu'un médecin, peu importe que l'algorithme soit une boîte noire. De même, si l'IA permet de lutter plus efficacement contre la fraude ou contre le non-recours (cf. Partie II), ou tout simplement si elle permet d'offrir un service public plus efficace et plus personnalisé, ou de libérer les agents de tâches chronophages et fastidieuses, il n'y a pas de raison de s'en priver.
C'est pourquoi le meilleur compromis possible semble être celui du principe de primauté humaine, élément clé de la construction d'une « IA publique de confiance », en vertu duquel une décision ne peut pas être prise par la machine seule : l'IA suggère, mais l'humain décide.
Si la mise en pratique de ce principe est complexe et différente selon les cas d'usage, elle a au moins le mérite de s'appliquer clairement en matière de lutte contre la fraude : aucun contrôle, aucun redressement ne peut être engagé sur le seul fondement d'un traitement informatique automatisé.
DEUXIÈME PARTIE
L'IA CONTRE LA
FRAUDE :
TOTEM FISCAL, TABOU SOCIAL
Les administrations de Bercy et les caisses de sécurité sociale gagneraient à se saisir davantage de l'IA, et notamment de l'IA générative, dans l'ensemble de leurs missions - et cela vaut pour le reste du service public. Toutefois, dans la sphère fiscale et sociale, c'est bien en matière de lutte contre la fraude que les avantages sont les plus évidents, et que les progrès pourraient être les plus rapides.
En mai 2023, le ministre chargé des Comptes publics, Gabriel Attal, a lancé un grand « plan de lutte contre les fraudes sociales, fiscales, et douanières ». Le 20 mars 2024, le Premier ministre, Gabriel Attal, en a tiré un premier bilan : les résultats de l'année 2023 sont en hausse, et de façon nette.

Ces résultats, dont il faut d'abord se féliciter, appellent toutefois deux questions. D'abord, l'augmentation des fraudes détectées est-elle le signe d'une augmentation des fraudes commises en général, ou - plus probablement - un indice de l'ampleur de ce qui reste encore à découvrir ?
Ensuite, quelle est la contribution réelle de l'IA à la hausse de ces résultats ?
L'intérêt principal de l'IA concerne la détection de la fraude, « premier maillon de la politique globale de lutte contre la fraude, [qui] précède et détermine l'efficacité » de tout le reste, comme le souligne la Cour des comptes dans son rapport de 2023 sur la fraude des particuliers. Or ce premier maillon est aussi notre maillon faible, et il est presque absent du plan de 2023, dont la plupart des mesures visent à renforcer les sanctions et améliorer la coopération entre services. Mais pour sanctionner, encore faut-il détecter.
L'IA est pourtant utilisée depuis plusieurs années pour détecter la fraude, mais de façon inégale et avec des technologies variées. Pour répondre à la question, il est donc nécessaire d'entrer dans le détail en distinguant les technologies utilisées selon leurs possibilités et leur niveau de maturité :
- le machine learning (apprentissage automatique) est le plus simple et donc le plus utilisé, mais sa part dans le datamining reste mineure ;
- le deep learning (apprentissage profond) est plus puissant mais quasi absent, exception faite de deux projets récents à la DGFiP et à la douane ;
- l'IA générative n'est pas utilisée du tout, alors qu'elle ouvre toute une nouvelle gamme de possibilités, jusque-là inenvisageables - mais avec, aussi, ses propres risques et ses propres limites.
Il faut insister sur ce point : lorsque l'on parle d'utilisation de l'IA pour lutter contre la fraude fiscale et sociale, ou dans le service public d'une manière générale, on parle en réalité d'outils qui sont très loin de la « frontière technologique », sans comparaison possible avec les innovations qu'on évoque ailleurs et qui sont aujourd'hui au coeur du débat public. Or rien ne justifie que l'État ne bénéficie pas des mêmes avancées que le secteur privé - ou des mêmes « armes » que les fraudeurs.
Il existe toutefois une différence notable entre Bercy et la sphère sociale :
- les administrations fiscales sont de loin les plus volontaristes : même si la contribution réelle de l'IA aux résultats du contrôle fiscal doit être relativisée, c'est là que le recours au machine learning est le plus ancien et le plus poussé, et c'est à la DGFiP et à la douane que l'on doit les deux seuls projets significatifs de deep learning ;
- les caisses de sécurité sociale apparaissent en revanche sur la défensive : il existe bien un recours au datamining, mais de moindre ampleur, et celui-ci semble peu, voire pas du tout, appuyé sur l'IA. Les raisons tiennent d'abord à une trop faible « culture » de la lutte contre la fraude, qui doit évoluer.
Les données fiscales et sociales : une opportunité exceptionnelle pour l'IA
La performance d'une IA dépend directement de la quantité et de la qualité des données utilisées pour son entraînement. L'enjeu ici ne concerne pas l'entraînement initial du modèle de base, mais son réentraînement sur des données métier spécifiques (fine-tuning).
Dans beaucoup de domaines, l'accès aux données constitue une difficulté majeure, sinon la principale. En matière de santé, par exemple, les algorithmes de deep learning ont besoin d'immenses quantités de données, et il s'agit souvent de données personnelles et sensibles, qu'il faut alors anonymiser, et qui ne peuvent être stockées et traitées que sur des infrastructures répondant à des critères très stricts - c'est tout le sens de la polémique autour de l'hébergement du Health Data Hub sur le cloud de Microsoft. En outre, les données médicales sont issues de sources multiples, souvent hétérogènes, et la plupart du temps payantes et soumises à diverses restrictions.
En comparaison, les administrations fiscales et sociales ont énormément de « chance » : les données utiles (pour la phase d'entraînement comme pour la phase d'utilisation de l'IA) sont des données internes, déjà disponibles, hébergées sur leur propre infrastructure physique, et dont l'exploitation est déjà autorisée par un cadre juridique protecteur (cf. infra : secret fiscal, encadrement de l'exploitation des données par le législateur, le Conseil constitutionnel et la Cnil, etc.).
Ces données - tous les impôts, toutes les cotisations et prestations sociales, toutes les déclarations en douane, et sur plusieurs décennies - sont en outre massives, exhaustives, fiables, homogènes, uniques et gratuites. Aucune autre administration, aucun autre service public ne se trouve dans une situation aussi favorable.
À ces données structurées viennent en outre s'ajouter toutes les données textuelles et autres données non structurées, devenues exploitables avec l'IA générative. Enfin, il faut ajouter aux données internes les données publiques générales (doctrine, etc.) et les données spécifiquement collectées en vue d'une analyse automatique, le cas échéant après autorisation du législateur (données collectées par la DGFiP ou Cyberdouane, par exemple).
I. LE DATAMINING N'EST PAS LE MACHINE LEARNING
A. LA DGFIP, PIONNIÈRE DU DATAMINING
Le premier usage de l'IA dans le cadre de la lutte contre la fraude concerne la programmation du contrôle fiscal, avec la généralisation du recours au datamining, un terme - surtout employé par la DGFiP - qui désigne le croisement et l'exploitation en masse des données détenues par l'administration : données déclaratives, données obtenues auprès des tiers (banques, etc.) ou d'autres services publics, données issues du renseignement fiscal, etc. Le datamining en matière fiscale est aujourd'hui utilisé de façon intensive par la majorité des pays membres de l'OCDE.
La DGFiP a recours au datamining depuis 2016, dans le cadre du programme « Ciblage de la fraude et valorisation des requêtes » (CFVR) créé en 2014 à titre expérimental, puis pérennisé en 2019. Ce programme, qui repose sur une infrastructure dédiée, est mis en oeuvre de façon centralisée par le pôle datamining du service juridique et du contrôle fiscal (SCJF). Il dispose d'une équipe dédiée de data scientists pour la conception et l'utilisation des algorithmes de croisement.

Les croisements effectués permettent de détecter et modéliser les anomalies et irrégularités fiscales, en comparant les données déclarées avec les données détenues par l'administration et avec les estimations statistiques. Le datamining couvre par exemple 50 risques pour les particuliers (IR, crédits d'impôt, droits de succession, résidence principale, etc.).
Le datamining n'entraîne en aucun cas une mise en oeuvre automatique des contrôles fiscaux : il vise uniquement à détecter des anomalies potentielles pour « proposer » un programme de contrôle aux services de terrain. Le déclenchement d'un contrôle ou l'établissement d'une décision opposable au contribuable sur la base d'un traitement automatique sont strictement interdits.
Le programme CFVR
L'arrêté du 21 février 2014 portant création d'un traitement automatisé de lutte contre la fraude, pris après avis de la Cnil et plusieurs fois élargi (2015, 2017, 2019, 2021), autorise la DGFiP à exploiter et croiser, aux seules fins de lutte contre la fraude, les données issues de SI limitativement énumérés, parmi lesquels figurent les SI suivants :
- comptes bancaires (FICOBA) et assurance-vie (Ficovie) ;
- compte fiscal des professionnels (ADELIE) et des particuliers (ADONIS) ;
- SI impôts : IR, IS, TF, TH, IFI... ;
- base nationale de données patrimoniales (BNDP) ;
- SI recouvrement ;
- SI contrôle fiscal : SIRIUS, ALPAGE ;
- échanges automatiques d'informations (EAI) entre administrations fiscales.
*
La collecte de données sur les réseaux sociaux et plateformes en ligne
Autorisée depuis 2020, elle permet par exemple à l'administration fiscale de repérer des activités occultes (prestations de coiffure, travaux, vente de voitures, locations meublées, etc.).
La collecte est cependant limitée et l'analyse repose sur des croisements « simples », sans IA.
Le Conseil constitutionnel et la Cnil ont restreint le dispositif aux seules informations accessibles publiquement - empêchant donc son utilisation sur les plateformes exigeant la création d'un compte utilisateur (Facebook, etc.). Cette dernière limitation a été levée par la loi de finances pour 2024.
À défaut d'être quantifiables, faute de données sur les emplois affectés à la détection de la fraude auparavant, les gains de productivité liés au datamining sont évidents : une équipe d'une dizaine de data scientists suffit désormais à programmer près de la moitié des contrôles fiscaux.
En revanche, comme le souligne la Cour des comptes, il est impossible de savoir si le datamining permet réellement de mieux détecter la fraude elle-même :
« Contrairement à de nombreux pays, la France ne dispose d'aucune évaluation rigoureuse de la fraude fiscale. (...) En l'absence d'estimation statistique, il est impossible d'établir quelle proportion de cette dernière est détectée, et si cette proportion a augmenté au cours des dernières années avec la mise en oeuvre d'outils plus puissants. Il s'agit là d'une carence majeure, à laquelle il doit être remédié. »
Cour des comptes, La détection de la fraude fiscale des particuliers, novembre 2023
Tout au plus peut-on noter qu'en dépit de la généralisation du datamining, les résultats du contrôle fiscal évoluent finalement assez peu : les 15,2 milliards d'euros mis en recouvrement en 2023 - qu'il ne faut pas confondre avec les sommes effectivement recouvrées, généralement bien plus faibles, mais non communiquées cette année - correspondent en réalité à un niveau déjà atteint à plusieurs reprises au cours des années précédentes, et la part des dossiers contrôlés faisant effectivement l'objet d'un redressement est restée constante depuis 2018 (environ 55 % pour les particuliers). Surtout, il existe un écart manifeste entre la part des contrôles issus du datamining d'une part (environ 50 %), et le montant des droits et pénalités notifiés sur ces contrôles d'autre part (seulement 2 milliards d'euros sur les 15,2 milliards d'euros).

S'agissant de la détection de la fraude, la plus-value du datamining apparaît donc assez limitée à ce jour. Comment l'expliquer ?
Une partie de la réponse tient sans doute au fait que le datamining et l'IA sont deux choses distinctes, et que la part du datamining qui s'appuie effectivement sur le recours à l'IA - en proportion des contrôles programmés comme des montants recouvrés - est incertaine, mais plus réduite, et en tout état de cause en deçà des possibilités théoriques.
L'indicateur de performance « Part des contrôles ciblés par IA et datamining » utilisé par la DGFiP ne permet pas - fort opportunément - de distinguer entre les deux.
En effet, la « base » du datamining consiste à collecter (« miner ») des données et à les croiser au moyen d'algorithmes « classiques », c'est-à-dire des « arbres de décision » fondés sur des règles logiques explicites et des critères et seuils de risque prédéfinis. Bien sûr, ces algorithmes utilisent aussi des méthodes statistiques simples (pour hiérarchiser les risques, etc.), mais ne relèvent pas pour autant de l'apprentissage automatique.
À ces croisements « simples » se sont progressivement ajoutés des traitements plus sophistiqués relevant de l'apprentissage automatique, mais là encore, leur degré de complexité est variable, et leur poids réel dans le datamining est inconnu. Il existe trois grandes méthodes d'apprentissage automatique :
- l'apprentissage supervisé est utile lorsque l'on sait déjà ce que l'on cherche : le modèle, entraîné sur les contrôles des années passées, apprend à reconnaître les caractéristiques des fraudes déjà connues (les données sont « étiquetées »). Cette technique, très répandue, est la plus utilisée par le pôle datamining de la DGFiP ;
- l'apprentissage non supervisé permet lui de révéler des comportements ou montages frauduleux, inhabituels, complexes, voire inconnus, en établissant lui-même des liens et corrélations statistiques - parfois insoupçonnables - entre les éléments (données « non étiquetées »). Mais cette technique, très puissante, est aussi plus difficile à maîtriser, et ne semble pas employée à grande échelle pour le datamining, d'après les informations disponibles ;
- l'apprentissage par renforcement permet à l'IA d'apprendre par l'expérience, grâce à un système de « récompense » : si le résultat est correct, la récompense est positive et l'IA conserve le paramètre testé, et si le résultat est incorrect, la récompense est négative et l'IA teste un nouveau paramètre. Il ne semble pas utilisé.
Enfin, si le pôle datamining utilise l'apprentissage automatique classique (machine learning), il n'a en revanche jamais recours à l'apprentissage profond (deep learning), pourtant à l'origine de la plupart des progrès récents en IA, et très prometteur en matière de lutte contre la fraude (cf. infra).
Il semble donc que la contribution réelle de l'IA au contrôle fiscal dans le cadre du datamining soit en fin de compte assez modeste, et qu'elle repose sur des modèles relativement basiques, bien loin de l'état de l'art de la technologie (sans même parler d'IA générative), et loin de ce qui se fait couramment dans les grandes entreprises pour répondre à leurs besoins métiers, allant de la prospection pétrolière aux services financiers, en passant par la publicité en ligne ou la modélisation des risques sur une infrastructure en réseau (SNCF, RTE, etc.).
Peut-être est-ce pour cela que le datamining n'a pas conduit à une hausse massive des résultats du contrôle fiscal : il a permis d'automatiser des recoupements auparavant effectués manuellement, débouchant sur des gains massifs et incontestables en termes d'efficacité (une petite équipe suffit désormais à établir l'essentiel de la programmation du contrôle fiscal), mais cela ne signifie pas forcément qu'il soit capable de détecter ce qu'un agent n'aurait pas pu voir.
Pour autant, la DGFiP a le mérite de s'être saisie du sujet assez tôt, notamment en comparaison d'autres pays ou d'autres administrations en France, et d'avoir su recruter en interne une équipe de spécialistes malgré les rigidités propres à l'administration (cloisonnement, statut, rémunération, etc.). Il reste qu'avec les progrès de l'IA, la marche à franchir est bien plus haute que cela : aujourd'hui, pour une administration ou une entreprise dont le métier est de traiter de l'information, dix data scientists, ce n'est tout simplement pas suffisant.
Une prise de conscience à l'échelle de l'État tout entier est nécessaire sur le sujet.
B. LA DOUANE : DES DONNÉES ET DES IDÉES
La douane, à l'instar de la DGFiP, est une administration qui dispose d'immenses quantités de données restées longtemps cloisonnées et peu valorisées, mais qui utilise de plus en plus le datamining.
Une étape importante a été franchie avec le lancement du programme « Valorisation des données », créé en 2019 et aujourd'hui rattaché à la délégation à la stratégie. Ce programme repose sur la mise en place d'un lac de données (datalake), infrastructure de déversement, de croisement et d'exploitation de l'ensemble des données issues des quelque 200 applicatifs métier de la DGDDI. À ce jour, ce programme a déjà donné naissance à une trentaine de nouveaux outils, pour la plupart encore en développement, destinés à faciliter le travail des agents dans des domaines variés.
Quelques applications issues du programme « Valorisation des données »
« Vision 360 des opérateurs économiques »
Outil de visualisation sur une carte des flux d'un opérateur (importations, exportations), par pays et par région, utilisé par les services chargés d'accompagner les entreprises à l'international.
« Minoration de valeur »
Outil de ciblage du SARC, en complément des méthodes classiques (ratio poids/valeur déclarée atypique, etc.).
« Résolution d'identité »
Cet outil permet d'identifier un même expéditeur ou destinataire dans le cas - fréquent - où il aurait « brouillé les pistes » en changeant par exemple quelques lettres de son nom.
Le datamining permet notamment un meilleur ciblage des flux de marchandises illicites : 25 % des prescriptions de contrôle du SARC (service d'analyse de risque et de ciblage) en matière de dédouanement, par exemple, doivent être issues du datamining (objectif 2023), selon une logique identique à celle de la DGFiP.
Lorsqu'un cas d'usage potentiel est identifié, les équipes du programme « Valorisation des données » peuvent faire appel aux 6 data scientists du pôle « Science des données » pour développer un outil - y compris en matière de machine learning, voire de deep learning (cf. infra : projet « 100 % scanning »).
Comme à la DGFiP, cependant, la grande majorité des outils et des croisements de données ne relèvent pas de l'IA mais de techniques classiques, et ceux qui utilisent l'apprentissage automatique sont rares et relativement simples. C'est le cas, par exemple, du projet « Résolution d'identité », qui permet d'identifier un même expéditeur ou destinataire qui aurait modifié quelques lettres de son nom. Là encore, l'administration fait au mieux, et 6 data scientists, c'est insuffisant.


C. QUI A PEUR DE LA FRAUDE SOCIALE ?
Par rapport aux administrations de Bercy, dont les moyens sont limités mais qui font preuve de volontarisme, les organismes de sécurité sociale apparaissent nettement sur la défensive. Il existe bien un recours au datamining dans le cadre de la lutte contre la fraude, mais celui-ci est à la fois plus récent, moins généralisé, et moins assumé.
Surtout, d'après les informations disponibles, celui-ci ne s'appuie pas sur l'IA, sauf à définir celle-ci comme le simple recours à des méthodes statistiques, mais en tout état de cause pas sur du machine learning complexe, et encore moins sur du deep learning ou de l'IA générative. Ainsi, l'algorithme utilisé par la CAF, objet d'une polémique en 2023, n'est qu'un « simple » croisement de données sur la base d'un modèle statistique.
L'algorithme « datamining données entrantes » (DMDE) de la CAF
Depuis 2011, la CAF utilise un algorithme de datamining pour orienter la programmation de ses contrôles parmi les quelque 13,8 millions de foyers d'allocataires. Les contrôles eux-mêmes sont effectués sur place (à domicile) par 700 contrôleurs assermentés, et aucune décision n'est prise sur la base d'un traitement automatisé, conformément au cadre posé par la loi et la Cnil.
L'algorithme, conçu par des statisticiens, calcule un « score de risque » (de 0 à 1) à partir d'une quarantaine de critères (sur les 300 informations que contient un dossier) correspondant aux facteurs de risque constatés sur les contrôles passés ayant révélé des irrégularités. Ce traitement a été autorisé par la Cnil.
Seules les données internes de la CAF sont utilisées : résidence en France, situation familiale (couple, parent isolé, etc.), professionnelle (en activité, demandeur d'emploi, etc.) et financière (revenus imposables et non imposables). Les informations ne sont pas croisées avec les données provenant d'autres organismes (Pôle Emploi notamment).
Exemples de critères utilisés par l'algorithme

Le Monde, « Profilage et discriminations : enquête sur les dérives de l'algorithme des CAF », 12 avril 2023, d'après les données communiquées par la Cnaf (code source, liste des variables et coefficients pour les algorithmes 2010-2014 et 2014-2020) et analysées par Lighthouse Reports
En 2021, 70 % des contrôles sur place étaient issus du datamining, mais seulement 1 % du total des contrôles de la CAF (ceux-ci se font principalement sur pièces, et sans datamining).
L'algorithme a été accusé de « discriminer les plus vulnérables », notamment par des associations comme La Quadrature du Net ou ATD Quart Monde. Dans la mesure où les aides versées par la CAF (RSA, prime d'activité, aides au logement, AAH, etc.) sont par définition destinées à un public plus vulnérable, le reproche est difficile à entendre, sauf à considérer qu'il est plus « juste » de contrôler complètement au hasard et d'ignorer les modèles statistiques. Toutefois, il est vrai que si les 40 critères sont fondés sur des calculs statistiques, la décision de les inclure ou non dans l'algorithme reste discrétionnaire. Avec l'apprentissage automatique non supervisé, ce problème n'existerait pas, puisqu'on ne donne aucun critère a priori à la machine : c'est elle qui les « découvre » elle-même. En un sens, c'est plus objectif.
On a aussi reproché à l'algorithme d'avoir pour seul objectif la lutte contre la fraude, ce que la CAF dément. Cet objectif de lutte contre la fraude doit pourtant être assumé, car il est une condition de la justice et de l'efficacité de notre système de redistribution. Il n'est cependant pas le seul objectif : l'algorithme vise à détecter des anomalies et pas à les caractériser, celles-ci pouvant également correspondre à des erreurs de bonne foi, à des erreurs internes, ou à des situations de non-recours. D'ailleurs, si les contrôles sur place issus du datamining donnent lieu à une réclamation de trop-perçu dans 50 % des cas (contre 1 % pour les contrôles en général), ils donnent aussi lieu à un versement en faveur des allocataires dans 27 % des cas, au titre de prestations dues mais non versées ou non réclamées.

De fait, c'est bien la même technologie qui permet de lutter contre la fraude et lutter contre le non-recours, et ne pas l'utiliser, c'est ne remplir aucun des deux objectifs.
En tout état de cause, la marge d'amélioration est importante : en 2023, la Cour des comptes a ainsi refusé de certifier les comptes de la Cnaf, la somme des « erreurs » (versements « indus » et « non versés à tort ») atteignant 5,8 milliards d'euros soit 7,6 % du montant total des prestations.
Les résultats de la lutte contre la fraude sociale viennent toutefois de connaître une amélioration très nette, comme l'a indiqué le Premier ministre (cf. supra). Les redressements notifiés par l'Urssaf, par exemple, ont augmenté de 50 %, à 1,2 milliard d'euros, et le montant des fraudes détectées par l'Assurance maladie de 50 % également, 466 millions d'euros. La même tendance est constatée pour l'Assurance vieillesse et la CAF.
S'il faut évidemment se féliciter de ces résultats, de tels écarts laissent tout de même songeur : soit c'est la fraude elle-même qui a subitement augmenté, dans tous les domaines en même temps, ce qui est peu vraisemblable, soit cette hausse spectaculaire est le signe que la lutte contre la fraude était très largement déficiente - et qu'il demeure sans doute d'importantes marges de progression.
En effet, ces résultats ont principalement été obtenus par un datamining « basique », avec de simples croisements de données, soit une technologie déjà disponible et maîtrisée en interne depuis une dizaine d'années, sans IA, et avec peu ou pas de croisements de données entre organismes ou administrations. Le Premier ministre a donc eu raison de relever les objectifs fixés en matière de lutte contre la fraude sociale.
Le recours au datamining et à l'IA dans la lutte contre la fraude n'est pas une solution miracle, et il pose évidemment des problèmes spécifiques. En revanche, il n'y a pas de raison que les enjeux soient différents dans la sphère fiscale et dans la sphère sociale. Il semble donc que le « retard » constaté depuis des années dans la sphère sociale tienne davantage à une moindre « culture » de la lutte contre la fraude, et cela n'est pas justifiable : « frauder, c'est voler », pour reprendre les mots du Premier ministre, et toutes les sommes ainsi perdues rendent notre système social à la fois moins efficace, moins équitable et moins généreux.
II. LE DEEP LEARNING : LES NEURONES ARTIFICIELS DE BERCY
Si l'apprentissage automatique est utilisé - à des degrés et pour une efficacité variables -, il n'y a en revanche presque aucun recours à l'apprentissage profond. Pour simplifier, on pourrait dire que l'IA sert à mieux détecter la fraude que l'on connaît, mais pas à identifier celle que l'on ne connaît pas. Ceci renvoie à un paradoxe classique en matière de contrôle fiscal : un contribuable qui déclare peu ou mal a plus de chance d'être « repéré » qu'un contribuable qui ne déclare rien.
Il y a cependant deux exceptions encourageantes, toutes deux à Bercy, et toutes deux dans le domaine de la reconnaissance d'images. Leur intérêt va bien au-delà de leur seul cas d'usage : il s'agit d'apporter « la preuve du concept » (proof of concept, ou POC).
A. BERCY SE JETTE À L'EAU : LE PROJET « FONCIER INNOVANT » DE LA DGFIP
Lancé en 2022 par la DGFiP, le projet « Foncier innovant » s'appuie sur l'IA pour automatiser l'exploitation des images aériennes publiques de l'IGN afin de détecter les constructions ou aménagements non déclarés, avec un test sur les piscines.

Le projet a été piloté par la Délégation à la transformation numérique (DTNum), en lien avec les services du cadastre (bureau et service national), et financé à 50 % par le Fonds pour la transformation de l'action publique (FTAP), pour un coût de 24 millions d'euros.

L'expérimentation menée sur 9 départements pilotes en 2022 a permis de confirmer le caractère taxable de plus de 20 000 nouvelles piscines, représentant près de 10 millions d'euros de recettes supplémentaires pour les communes (taxe foncière). Le dispositif a donc été généralisé en 2023 à l'ensemble de la métropole (la Corse et l'Outre-mer devraient suivre), pour environ 150 000 piscines potentiellement taxables au total, soit une part non négligeable (5 %) des 3 millions de piscines enterrées que compte la France.
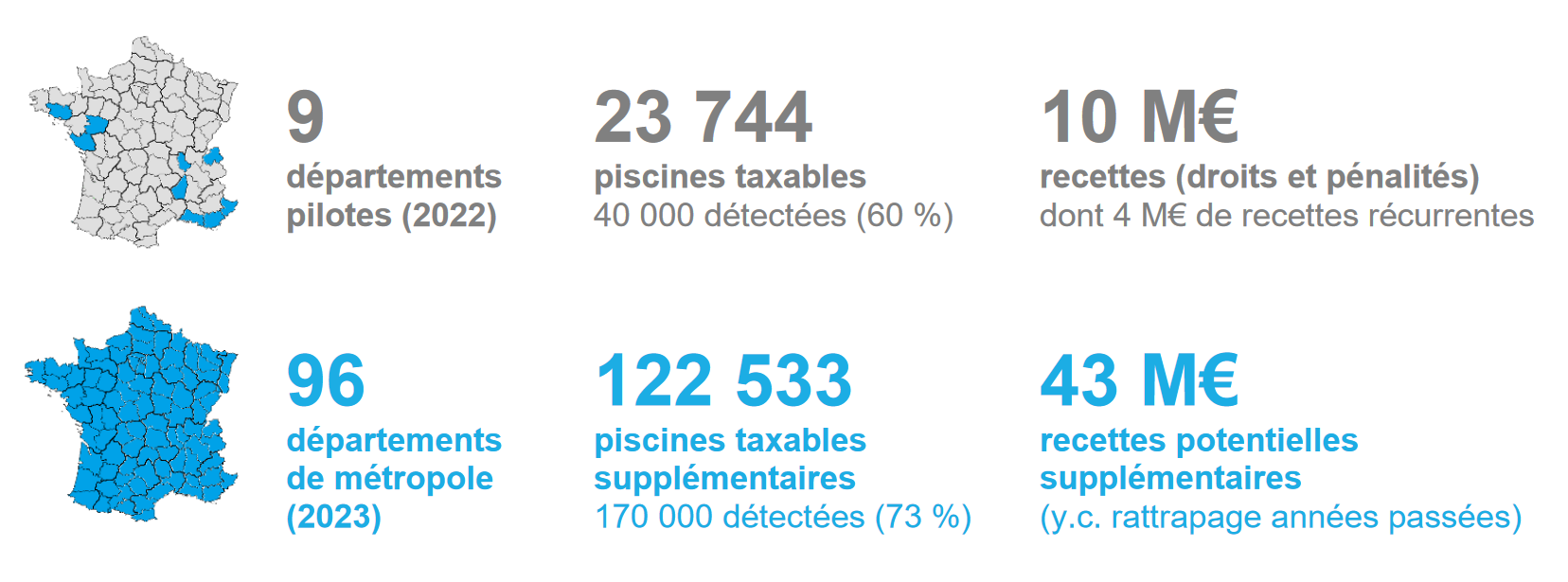
Comment ça marche ?

1. À partir des images aériennes publiques de l'IGN, accessibles à tous sur le Géoportail, un algorithme d'apprentissage profond extrait les contours des bâtiments et piscines.
Deep learning et reconnaissance visuelle : afin d'extraire les objets sémantiques (les contours des bâtiments) des images satellitaires, l'algorithme utilise un réseau de neurones qui, par couches successives, va d'abord affecter une classe à chaque pixel en fonction de sa couleur (bâti/non-bâti/eau, etc.), avant de transformer ces données segmentées (la grille de pixels) en objets vectoriels (les polygones formant les contours de chaque bâtiment).
2. Les données sont comparées avec celles du plan cadastral et d'autres données textuelles détenues par la DGFiP (déclaration préalable aux services d'urbanisme, permis de construire, déclaration d'achèvement, etc.), pour vérifier que ces éléments sont correctement soumis aux impôts locaux.
3. Un agent vérifie systématiquement chaque anomalie potentielle détectée, directement dans l'application métier ICAD.
4. Si l'anomalie est confirmée, le propriétaire est invité à régulariser sa situation sur impots.gouv.fr.
La sécurité des données : seules les données - publiques - de l'IGN font l'objet d'un traitement sur le cloud de Google, le croisement avec les données fiscales et cadastrales s'effectuant exclusivement sur les infrastructures internes de la DGFiP.
Le succès est donc incontestable, et le projet est d'ores et déjà rentabilisé, les sommes mises en recouvrement couvrant déjà près de deux fois l'investissement initial. Certes, l'enjeu financier est minime en comparaison du rendement total des impôts fonciers, et tout à fait dérisoire au regard des pertes causées par la fraude fiscale, mais l'intérêt de cette expérimentation dépasse son seul cas d'usage. Les principaux acquis sont :
- la preuve de l'intérêt de la technologie, qui pourrait être étendue facilement à l'ensemble du foncier bâti et non bâti (garages, abris de jardin, vérandas, etc.), non seulement à la DGFiP mais aussi à la douane (viticulture) ou même hors de la sphère fiscale (agriculture, etc.) ;
- l'internalisation des compétences : tout en s'appuyant dans un premier temps sur des prestataires externes (Capgemini et Google), la DGFiP a recruté en interne ses propres spécialistes. La DTNum dispose donc aujourd'hui d'une compétence complète en deep learning (contrairement au pôle datamining) ;
- la preuve des vertus de l'agilité dans la conduite du changement, dont les piliers sont : une équipe restreinte aux compétences transversales (y compris venues de l'extérieur), une démarche fondée sur l'expérimentation, la validation des concepts et l'amélioration incrémentale (à la différence des grands projets SI habituels), et enfin une attention portée aux retours du terrain (notamment en ce qui concerne l'ergonomie et la simplicité d'utilisation des outils).
Un outil de fiabilisation du cadastre
Au-delà de l'objectif de lutte contre la fraude, cet outil pourrait permettre d'automatiser des vérifications jusqu'à présent réalisées ponctuellement et manuellement.
Le traitement des images aériennes par l'IA permettrait ainsi une mise à jour des bases foncières et des données cadastrales automatique, systématique, homogène sur tout le territoire et en continu, les photos de l'IGN étant actualisées tous les ans par tiers des départements.
B. POC EN STOCK : LE PROJET « 100 % SCANNING » DE LA DOUANE
Le projet « 100 % scanning », porté par le pôle « Science des données » de la délégation à la stratégie de la douane, appelle les mêmes remarques. Il s'agit cette fois d'utiliser un algorithme de deep learning pour analyser les images de scanners à rayons X afin de détecter les produits stupéfiants envoyés par fret express et postal, alors que les flux liés au e-commerce explosent. L'expérimentation porte sur la détection du cannabis et de la cocaïne.
 |
 |
|
|
Le e-commerce : La douane a fait du e-commerce l'une de ses priorités. Le défi est de taille : comme l'avait souligné la commission des finances du Sénat dès 2014, l'atomisation des envois - très nombreux mais représentant chacun un faible enjeu individuel - prive de toute efficacité les méthodes habituelles de contrôle des marchandises, pensée pour le commerce traditionnel (conteneurs, camions, etc.). Il est ainsi tout à fait illusoire d'espérer pouvoir contrôler chaque paquet individuel, et quand bien même une infraction serait constatée, la lourdeur de la procédure (qui est judiciaire) et la quasi-certitude qu'elle n'aboutisse pas (le destinataire n'est pas responsable du contenu de l'envoi) conduit la plupart du temps la douane à saisir la marchandise, sans autre suite. Dès lors, ces envois échappent en grande partie à la taxation (droits de douane et TVA à l'importation), et donnent lieu à d'innombrables trafics (stupéfiants, cigarettes, etc.), facilités notamment par les plateformes de vente en ligne du darknet. |
La douane : « Administration de la frontière et de la marchandise », la DGDDI est directement aux prises avec le monde matériel : dédouanement des importations, contrôles de conformité (normes européennes, contrefaçon, etc.), e-commerce, lutte contre les trafics (armes, stupéfiants, espèces protégées, etc.), mais aussi contrôles migratoires, surveillance des façades maritimes ou encore protection de l'environnement - des « métiers » qui sont autant de terrains d'expérimentation potentiels pour l'IA. |
Si l'objectif à terme est de couvrir 100 % des envois, le dispositif n'est pas encore opérationnel à ce jour : il faut encore finaliser l'acquisition des scanners, puis assurer leur intégration dans les SI métier de la douane, c'est-à-dire passer du POC (proof of concept) à la production (le déploiement), une étape toujours très complexe puisqu'elle implique, cette fois, les directions métier et la DSI. L'intégration à la chaîne de traitement des colis au sein des centres logistiques est aussi un défi à part entière.
L'algorithme de détection, en revanche, est prêt - et les premiers tests ont donné d'excellents résultats, avec une précision d'environ à 80 % dans la détection d'envois contenant des stupéfiants.
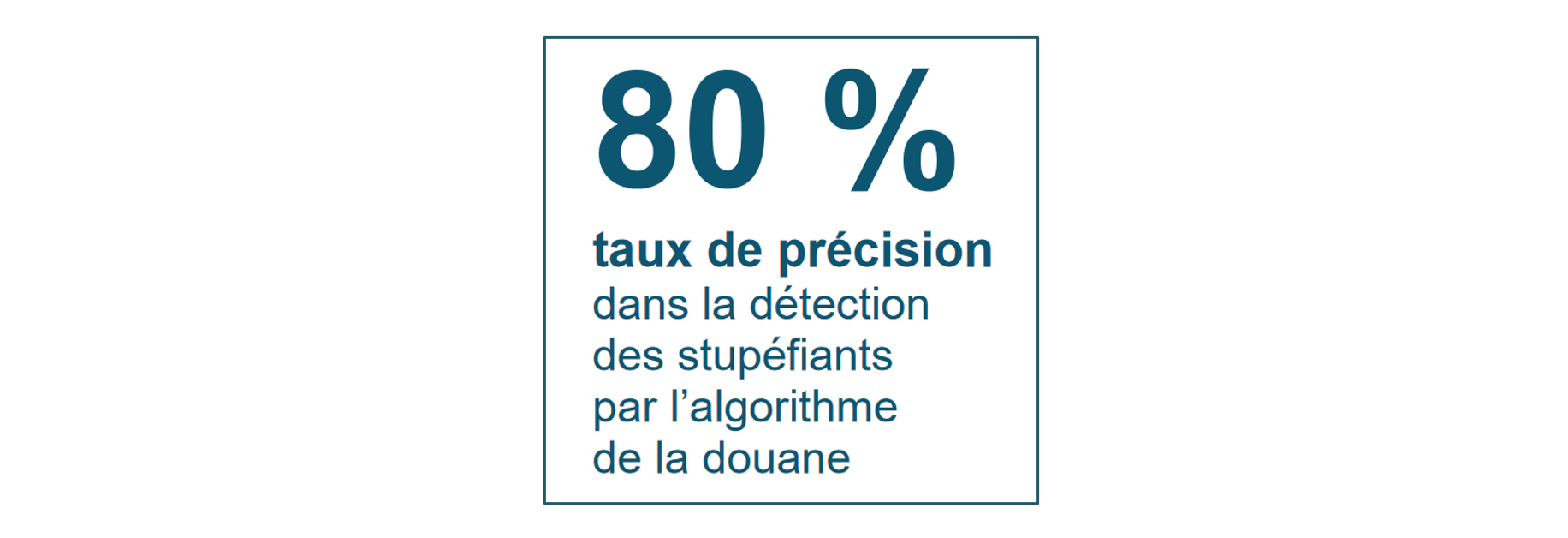
Là encore, le projet présente un intérêt bien au-delà de son premier cas d'usage. Ses principaux acquis sont :
- la preuve du concept, avec une technologie qui pourrait être facilement étendue à la détection d'autres types de flux illicites : autres stupéfiants, argent liquide, armes ou encore produits du tabac, dont la vente en ligne est interdite, et dont la forme est aisément reconnaissable (du moins pour les cigarettes). Il s'agit d'ailleurs de l'une des mesures annoncées dans le cadre du plan tabac 2023-2025 ;
- la maîtrise de la technologie : l'algorithme est indépendant du matériel utilisé et donc des fabricants de scanners et prestataires extérieurs. Cette technologie dont la douane est propriétaire pourrait être valorisée, par exemple dans le cadre d'une coopération internationale ou européenne. Les mêmes remarques valent pour les données d'entraînement, ici une vaste bibliothèque d'images de colis (frauduleux ou non), un actif précieux, valorisable et susceptible d'être enrichi avec le temps ;
- l'internalisation des compétences : si la douane a fait appel à un prestataire extérieur (Capgemini) lors du développement de l'algorithme, elle a en parallèle développé sa propre compétence en interne. Compte tenu de la taille réduite des équipes et du turnover inhérent à la matière, le véritable défi consistera toutefois à maintenir cette compétence dans la durée.
Ces deux POC - « Foncier innovant » à la DGFiP et « 100 % scanning » à la douane - doivent être salués et étendus à d'autres cas d'usage similaires, mais il ne faut pas pour autant s'en satisfaire : il est possible, et nécessaire, d'aller beaucoup plus loin grâce au deep learning.
D'une part, ce sont en fait tous les contrôles basés sur l'imagerie qui gagneraient à intégrer une couche d'IA pour analyser les données et détecter les fraudes, en particulier à la douane où les flux physiques sont nombreux (conteneurs, véhicules, passagers, etc.) et les matériels de détection variés (RX, photos aériennes, radars, etc.). La DGDDI est d'ailleurs en train d'acquérir une dizaine de camionnettes « backscatters », des scanners mobiles et polyvalents permettant de contrôler tout type de véhicule en 60 secondes, et pouvant être déployés avec flexibilité dans les ports et sur les axes routiers et autoroutiers.
Une telle perspective pose toutefois des questions délicates, illustrant parfaitement ce « dilemme de l'efficacité » auquel l'IA confronte l'action publique en général (cf. encadré ci-après).
D'autre part, si la reconnaissance visuelle est un domaine ancien et important de la recherche en IA, avec des applications nombreuses (diagnostic médical, conduite autonome, etc.), ce n'est qu'un domaine parmi d'autres, et surtout ce n'est pas le domaine qui présente le plus d'intérêt pour la lutte contre la fraude fiscale et sociale, où d'autres types de données non structurées - et notamment textuelles - pourraient être exploitées par des algorithmes de deep learning.
« 1 % scanning », ou le dilemme de l'efficacité
Si l'algorithme de la douane est efficace pour détecter les produits illicites dans les petits colis individuels, pourquoi ne pas utiliser l'IA contrôler l'ensemble des conteneurs transportés par voie maritime, par lesquels transite l'essentiel du commerce international, et donc l'essentiel du trafic de stupéfiants, ou encore l'ensemble des passagers des vols Cayenne-Orly, dont on estime que 20 % à 30 % sont des « mules », qui pour la plupart ne sont pas appréhendées ?

La technologie de base est la même : il s'agit d'apprendre à une IA à reconnaître des motifs récurrents sur des images fournies par des scanners. Pour la première fois dans l'histoire, il existe une solution technologique - l'usage combiné d'instruments de détection et de l'IA - qui permettrait en théorie de contrôler l'ensemble des conteneurs, en détectant les fraudes avec une efficacité sans précédent, et avec un impact minimal sur la durée d'immobilisation.
Certes, la fraude s'adapte, et il existe des obstacles pratiques et financiers à court terme. À long terme, toutefois, rien ne l'interdit, et l'argument du coût n'est pas valable : un scanner portuaire constitue bien sûr un investissement lourd, mais celui-ci doit être comparé aux gains potentiels (en termes de taxation comme de lutte contre les trafics) qui résulteraient de la possibilité d'examiner potentiellement tous les conteneurs sans les immobiliser.
La véritable raison est ailleurs : sans réflexion profonde sur les objectifs poursuivis, à organisation inchangée et à droit constant, l'IA risquerait, pour ainsi dire, d'être « trop » efficace. Cette question doit être prise au sérieux.
Une part non négligeable du commerce international relève de la fraude, qu'il s'agisse de trafics illicites ou de non-paiement des droits et taxes, et il est vraisemblable que cette fraude échappe dans son immense majorité aux États. Si demain une technologie permettait de détecter cent fois, mille fois plus de trafics, l'administration n'aurait tout simplement pas les moyens de faire face à l'ampleur de la tâche, du moins à droit constant et à organisation inchangée (procédure judiciaire, etc.).
En outre, même en admettant que l'administration se donne les moyens d'intervenir sur les fraudes ainsi détectées pour les empêcher, ce gain d'efficacité se paierait directement par une perte massive d'attractivité pour les ports français, au profit de destinations où les contrôles sont plus permissifs - certains pays, en Europe, s'en sont d'ailleurs fait une spécialité. En effet, les conséquences ne concerneraient pas que les fraudeurs : si des stupéfiants sont détectés dans un chargement, c'est tout le conteneur qu'il faut ouvrir, tout le camion qu'il faut immobiliser, et toute la chaîne logistique qui s'en trouve perturbée.
Le contrôle des marchandises relève d'un arbitrage implicite entre efficacité de la lutte contre la fraude d'une part, et attractivité économique d'autre part. Avec les méthodes de détection traditionnelles (contrôle documentaire lors du dédouanement, inspections aléatoires, renseignement, etc.), les moyens sont limités et l'arbitrage entre efficacité et attractivité se fait « naturellement » : certaines fraudes sont détectées et entraînent une intervention, d'autres non. Demain, il sera peut-être nécessaire de faire cet arbitrage beaucoup plus explicitement : « combien de tonnes de cocaïne sommes-nous prêts à accepter sur notre territoire pour maintenir la compétitivité de nos ports ? ».
Cet exemple, certes théorique, illustre un point essentiel : l'IA, en raison même de son efficacité sans précédent, pourrait nous obliger à nous poser des questions qui, jusqu'à maintenant, ne se posaient pas.
Ce « dilemme de l'efficacité » se pose dans les mêmes termes pour toute l'action publique, et donc pour toute la sphère fiscale et sociale.
III. L'IA GÉNÉRATIVE : FRAUDE COMPLEXE, POIDS DU TEXTE
Si l'IA d'une manière générale apparaît sous-utilisée dans la lutte contre la fraude, l'IA générative, quant à elle, reste à ce jour totalement absente. Elle ouvre pourtant la voie à toute une nouvelle gamme de possibilités, du fait de ses capacités spécifiques en matière de traitement des données non structurées, et notamment des données textuelles, y compris en langage naturel.
Bien sûr, il n'y a ni solution miracle, ni produit sur étagère : on ne parle pas ici d'utiliser ChatGPT pour faire du contrôle fiscal, mais plutôt de s'appuyer sur les possibilités offertes par les grands modèles de langage généralistes pour concevoir des outils spécifiques et adaptés à la matière - ce qui demandera du temps et des moyens, des précautions et de l'imagination, des essais et des erreurs.
Un premier avantage de l'IA générative est de permettre le décloisonnement de l'information (cf. Partie I), défi majeur pour des administrations dont les applications sont historiquement construites en silo et peu interopérables. C'est notamment le cas à la DGFiP, comme l'a plusieurs fois souligné la Cour des comptes au cours des dernières années. La priorité, bien sûr, est de poursuivre l'effort de modernisation et de refonte des SI, mais ces grands chantiers informatiques sont longs, coûteux et risqués. Dans ce contexte, l'IA générative pourrait avoir un intérêt, au moins comme expédient, voire de façon pérenne comme interface ergonomique, sous la forme d'un chatbot - « PilatGPT » ? - à la disposition des agents du contrôle fiscal pour recouper les informations.
Le contrôle fiscal à la DGFiP : un cas d'école du cloisonnement des systèmes d'information
« L'architecture des SI utilisés dans le cadre du contrôle fiscal repose sur des bases de données et des applications très nombreuses, anciennes, peu ergonomiques et souvent non interopérables. Ces bases ont été construites pour répondre à des besoins métiers spécifiques, alors que la détection des risques de fraude fiscale suppose souvent de rapprocher les données. Ces constats restent largement d'actualité. La conception en silo des SI [...] rend difficile, voire impossible la traçabilité des actions qui ponctuent un dossier de fraude, de la détection d'une anomalie au recouvrement des sommes éludées et des pénalités après contrôle. [...]
« Pour [y] remédier, la DGFiP a lancé en 2018 le projet PILAT, outil unifié de pilotage et d'analyse de la chaîne du contrôle fiscal [...]. Mais PILAT accuse aujourd'hui un retard de plus de deux ans et sa mise en service est désormais attendue pour la fin du premier trimestre 2024 [...]. Le coût prévisionnel du projet a presque triplé, passant de 36 millions d'euros estimé en 2017 à 103,2 millions d'euros en 2023.
« La DGFiP assure que PILAT permettra de suivre une chaîne continue [...]. Toutefois, dans la première version de l'application, il n'y aura toujours pas de correspondance stricte entre motifs de contrôle et irrégularités constatées (celles-ci pouvant différer des premiers), ce qui risque de nuire, de manière persistante, à l'évaluation de la pertinence du motif de programmation. »
Source : Cour des
comptes, La détection de la fraude fiscale des
particuliers,
rapport d'initiative citoyenne, novembre 2023
Surtout, le grand intérêt de l'IA générative tient à ses capacités en matière de traitement du langage naturel : après les chiffres, ce sont désormais les textes, aussi divers et hétérogènes soient-ils, qui peuvent faire l'objet d'une exploitation automatisée. Si l'ensemble du contrôle fiscal pourrait s'en trouver « augmenté », plusieurs domaines en particulier pourraient y gagner en efficacité, en raison de la place importante des textes et de la complexité des tâches et procédures. Ces domaines se recoupent en partie :
- la lutte contre la fraude et l'évasion fiscales internationales, qu'elle soit le fait des particuliers ou des entreprises ;
- le renseignement fiscal et les enquêtes fiscales, au niveau administratif comme judiciaire ;
- les dossiers à fort enjeu et la fraude complexe ;
- la lutte contre la fraude sur Internet.
Le cas de la lutte contre la fraude et l'évasion fiscales internationales
Dans ce domaine, les données textuelles comptent souvent davantage que les chiffres. Par exemple, pour la taxation des bénéfices d'une multinationale, l'enjeu n'est pas tant de connaître le montant du chiffre d'affaires que de déterminer la part de celui-ci qui doit être soumise à l'impôt sur les sociétés sur le territoire français. L'interprétation de la loi fiscale et le raisonnement juridique ont ici une importance cruciale, car ils déterminent la frontière entre ce qui relève de l'optimisation légale d'une part, et les pratiques illégales (voire frauduleuses) d'autre part.
Cette tâche implique le traitement d'informations à la fois nombreuses et hétérogènes, avec des données structurées (comptables) et non structurées (textuelles), avec :
- d'une part, les données déclarées par les contribuables ou communiquées par des tiers : documentation relative aux prix de transfert, mémoires et analyses juridiques, etc. ;
- d'autre part, les documents de référence de l'administration : textes législatifs et réglementaires, normes européennes, conventions fiscales, rescrits, doctrine, jurisprudence, description des montages frauduleux, circulaires et instructions diverses, etc.
Les données sont d'autant plus hétérogènes qu'elles proviennent fréquemment de sources étrangères (déclaration souscrite dans un autre pays, information communiquée par une administration étrangère, etc.). À défaut de faire foi devant un juge, une traduction par une IA générative pourrait a minima faire gagner un temps précieux aux agents dans leur travail - à condition, bien sûr, de ne pas utiliser directement ChatGPT pour traduire des documents couverts par le secret fiscal.
Enfin, pour les dossiers les plus complexes, les procédures peuvent prendre des années, à la fois au stade administratif (enquête fiscale, vérification de comptabilité, recours hiérarchique, etc.) et au stade judiciaire (enquêtes pour fraude fiscale, blanchiment, etc.). L'IA générative est capable de résumer dix ans de procédure en deux pages, de faire ressortir les points importants, et demain, avec un peu de fine-tuning, de repérer des erreurs ou de suggérer d'autres approches. De telles capacités ne peuvent être ignorées.

TROIS PRIORITÉS POUR AVANCER
Les développements qui précèdent donnent une idée du potentiel de l'IA et de l'IA générative dans le cadre des missions de collecte de l'impôt, de versement des prestations sociales et de lutte contre la fraude. Il reste à présent à se saisir de ce potentiel.
Les trois grandes priorités sont les suivantes : identifier les usages, clarifier les objectifs, et s'en donner les moyens. Les enjeux sont connus, ils ont été récemment soulignés par la Commission IA, et ils ne sont pas propres aux administrations fiscales et sociales.
« Les systèmes d'IA devront être mis au profit de la qualité du service public. L'IA peut améliorer le service public, en contribuant à personnaliser l'éducation, à accorder plus de temps aux patients, à mieux accompagner et anticiper les transitions professionnelles, à réduire la bureaucratie. Nous obtiendrons ces gains à condition de faire la mue de nos institutions. De l'évolution des infrastructures numériques à la conduite de projets d'IA, la mobilisation des administrations publiques sur les enjeux tenant à l'IA doit être accélérée, amplifiée, généralisée et déclinée par service public. »
Rapport de la Commission IA, mars 2024
I. IDENTIFIER LES USAGES
Il faut, tout d'abord, avoir une idée aussi claire que possible de ce que l'IA peut faire, et de ce qu'elle ne peut pas faire, du moins en l'état actuel des technologies, en distinguant :
- d'une part, les tâches qui peuvent être confiées à l'IA, parce qu'elles se prêtent à une approche statistique et probabiliste : c'est le cas de la détection de la fraude, mais aussi de tout ce qui concerne le traitement du langage naturel (analyse, résumé, génération de texte, traduction, etc.) ;
- d'autre part, les tâches qui ne peuvent pas être confiées à l'IA, parce qu'elles impliquent un calcul ou un raisonnement qui n'admet qu'une seule solution et/ou qu'elles doivent être entièrement transparentes et explicables, par exemple le calcul de l'impôt ou l'évaluation de l'éligibilité à une aide sociale. La bonne nouvelle est que les systèmes classiques font tout ceci très bien, et depuis longtemps.
Rappel
· Le machine learning et le deep learning sont adaptés pour traiter des données structurées et normalisées, notamment les chiffres.
· L'IA générative et les large language models excellent dans le traitement du langage naturel et des données non structurées et hétérogènes, notamment les textes.
II. CLARIFIER LES OBJECTIFS
Une fois les usages possibles identifiés, il faut dire ce que l'on en attend, en fixant des objectifs clairs et assumés.
A. TENIR ENFIN LES PROMESSES DU NUMÉRIQUE
L'IA doit être mise au service de l'intérêt général et de l'amélioration de la qualité du service public, à la fois pour les agents et pour ses usagers. Elle a le potentiel de le rendre non seulement plus efficace, mais aussi plus humain, c'est-à-dire plus simple, plus accessible, plus proche et plus équitable.
B. ASSUMER L'OBJECTIF D'ÉCONOMIES BUDGÉTAIRES
L'IA va permettre d'automatiser certaines tâches, et ces gains de productivité doivent se traduire en économies budgétaires : il en va de la bonne gestion des deniers publics, et donc de l'intérêt général. Cet objectif doit être assumé. Pour autant, il n'implique en tant que tel aucun effet automatique sur l'emploi : ce sont avant tout des tâches qui sont amenées à disparaître, et des métiers qui sont appelés à se transformer, non seulement au bénéfice des usagers, mais aussi des agents eux-mêmes.
C. GARANTIR LA PROTECTION DES DROITS FONDAMENTAUX
Enfin, le recours à l'IA ne doit pas se faire au détriment de la protection des libertés individuelles et des droits fondamentaux, et en particulier de la protection des données personnelles. Il faut ici distinguer les enjeux liés à la technologie - l'IA et l'IA générative - et les enjeux liés à son domaine d'application - l'impôt, les prestations sociales et la lutte contre la fraude.
En ce qui concerne le domaine d'application, et notamment en matière de lutte contre la fraude, le recours croissant à des technologies numériques potentiellement intrusives a conduit le législateur et le juge à mettre en place un régime particulièrement protecteur des droits et libertés individuelles, fondé sur des dispositions spécifiques (cf. encadré), qui s'ajoutent aux garanties plus anciennes dont bénéficie le contribuable (secret fiscal, garanties procédurales, etc.) et aux dispositions d'application générale, notamment la loi Informatique et libertés (loi Cnil) et le règlement général sur la protection des données (RGPD) ainsi qu'aux principes constitutionnels (vie privée, etc.). À l'avenir, l'usage de l'IA à des fins de lutte contre la fraude devra être encadré de la même manière.
L'encadrement des outils de détection de la fraude fiscale : quelques exemples
Le Conseil constitutionnel admet de longue date que la lutte contre la fraude fiscale, objectif à valeur constitutionnelle (OVC), permet au législateur d'apporter des aménagements aux droits et libertés individuelles. Avec l'usage croissant des nouvelles technologies, le juge constitutionnel a toutefois resserré l'encadrement des pouvoirs de l'administration fiscale, notamment en amont de la phase de contrôle, c'est-à-dire au stade de la détection.
Les croisements de données automatisés - qu'ils utilisent l'IA ou non - doivent donc être expressément autorisés et encadrés par la loi et faire l'objet d'une déclaration préalable, voire le plus souvent d'un avis de la Cnil. On peut notamment citer les exemples suivants :
- l'usage du droit de communication à des fins de détection générale (communication des « fadettes » par exemple), qui n'était pas encadré en tant que tel, a été restreint en 2019 : il est désormais limité à la recherche des infractions fiscales les plus graves (majoration de 80 %) et doit être autorisé par un magistrat indépendant saisi par le procureur de la République ;
- la collecte automatisée (webscrapping) de données sur les réseaux sociaux, autorisée à titre expérimental en 2020 et prolongée pour deux ans à partir de 2024, a été limitée par le Conseil constitutionnel et la Cnil aux seuls contenus publiquement accessibles, ce qui excluait toute collecte sur les plateformes où la création d'un compte utilisateur était nécessaire. La loi de finances pour 2024 a cependant levé cette dernière restriction ;
- le datamining et les échanges d'informations entre administrations doivent être expressément autorisés par le législateur et la Cnil. L'encadrement porte sur les données (limitativement énumérées), les finalités (ici la lutte contre la fraude) et la durée.
Des dispositions similaires existent pour la douane (webscrapping sur les sites de vente en ligne de tabac, par exemple) et les organismes de sécurité sociale.
En ce qui concerne la technologie elle-même, les spécificités de l'IA et en particulier des grands modèles généralistes d'IA générative sont susceptibles de faire émerger de nouveaux risques pour les droits et libertés individuelles. C'est tout l'enjeu de l'AI Act : protéger les droits fondamentaux tout en encourageant l'innovation.
Le texte proposé par la Commission européenne avait dans un premier temps suscité les réserves de la France, qui redoutait que les obligations prévues ne pèsent sur les entreprises les plus innovantes, à commencer par la startup française Mistral AI, l'un des rares concurrents européens crédibles aux acteurs américains, et souhaitait donc limiter la publication du résumé des données d'entraînement (en passant par un « tiers de confiance ») et relever le seuil à partir duquel s'appliquent les obligations renforcées. Les réserves de la France ont finalement été levées et un accord a été signé le 2 février 2024, conduisant à l'adoption de l'AI Act le 13 mars.

Fondée en avril 2023 par trois chercheurs français, Arthur Mensch, Guillaume Lample et Timothée Lacroix, Mistral AI développe des LLM (open source et propriétaires) concurrents de ceux des grands acteurs américains (OpenAI, Google, etc.), dont :
- Mistral 7B (sept. 2023) : LLM open source avec 7 milliards de paramètres, soit bien moins que ses concurrents, ce qui le rend intéressant pour des usages spécialisés.
- Mistral 8x7B (déc. 2023) : LLM open source avec 47 milliards de paramètres.
- Mistral Large (févr. 2024) : LLM propriétaire (modèle fermé), disponible via le cloud de son nouveau partenaire Microsoft, et dont la performance est proche de celle de GPT-4.
En février 2024, elle lance aussi Le Chat, un chatbot similaire à ChatGPT bâti sur ses propres LLM.
Suite à une levée de fonds de 385 millions d'euros en décembre 2023, la société est valorisée à 2 milliards d'euros, ce qui en fait l'un des leaders européens en matière d'IA.
L'enjeu principal, désormais, concerne la mise en oeuvre de l'AI Act, ce qui impliquera de préciser les modalités concrètes d'application de chaque mesure en fonction des différents domaines d'application. En ce qui concerne les missions d'intérêt général relevant de la sphère fiscale et sociale, les enjeux semblent a priori limités. Le seul point de vigilance concerne l'interdiction de tout système de « notation sociale », qui vise principalement les systèmes de « crédit social » existant dans certains pays - la Chine, notamment -, mais qui au sens large pourrait concerner tout traitement de données visant à attribuer un « score » ou un « coefficient » quelconque à un dossier individuel. Une telle définition maximaliste est évidemment impensable, puisqu'elle conduirait de facto à interdire l'informatique dans le service public : un permis de conduire à points ou un dossier sur Parcoursup ne sont rien d'autre qu'un système de notation.
L'AI Act, entre protection des droits fondamentaux et soutien à l'innovation
Présenté en 2021 par le commissaire au marché intérieur, Thierry Breton, le projet de règlement européen sur l'intelligence artificielle, ou AI Act, a été élaboré avant l'apparition de ChatGPT et la diffusion spectaculaire de l'IA générative et des large language models (LLM).
Consciente de la difficulté qu'il y aurait à réguler une technologie aux évolutions si rapides, la Commission a fait le choix d'une régulation des usages, en classant les systèmes d'IA (SIA) par niveau de risque pour les droits fondamentaux :

Un Bureau de l'IA, conseillé par un groupe scientifique d'experts indépendants, sera créé au sein de la Commission européenne pour superviser les modèles d'IA à usage général et faire appliquer des règles communes dans les États membres. Les amendes peuvent atteindre 35 millions d'euros ou 7 % du CA mondial (en cas de violation pour les règles sur les SIA interdits). Des plafonds plus faibles sont prévus pour les PME et les startups. L'AI Act ne sera pas applicable aux SIA utilisés exclusivement à des fins militaires ou de défense, ni aux SIA utilisés aux seules fins de la recherche et de l'innovation.
Négocié pendant plus de deux ans et révisé pour tenir compte du développement de l'IA générative, l'AI Act a fait l'objet d'un accord provisoire entre le Parlement et le Conseil, le 9 décembre 2023, puis d'un compromis final le 2 février 2024, suite à la levée des réserves de la France. Il a été adopté le 13 mars 2024 et entrera en vigueur progressivement à partir de mai 2024, avec un délai allant jusqu'à 36 mois pour les applications à risque élevé.
Comme RGPD avant lui, l'AI Act constitue une première mondiale.
Pour autant, il conviendra de faire preuve de vigilance, et ceci à chaque fois qu'un nouveau cas d'usage de l'IA dans le domaine fiscal ou social se présentera.
La Cnil aura ici un rôle fondamental à jouer, et elle s'est d'ailleurs déjà largement saisie du sujet, avec la création d'un service dédié à l'IA, la publication de « fiches pratiques » à destination des développeurs, et la mise en place d'un dispositif d'accompagnement (« bac à sable ») pour des projets d'IA dans le service public, notamment dans le domaine de la santé. Ses moyens devront être renforcés, comme le propose la Commission IA.
« Notre Commission recommande de poursuivre la modernisation de notre approche de la donnée en conjuguant mieux protection et innovation. [...] Nous recommandons notamment de supprimer des procédures d'autorisation préalable d'accès aux données de santé et de réduire les délais de réponse de la Cnil. Ce mouvement devrait s'accompagner d'une réforme du mandat qui est confié à la Cnil, pour y intégrer un objectif d'innovation. Cette évolution impliquera un ajustement de la composition de son collège, pour qu'une palette plus large de compétences soit représentée (innovation, recherche...), et un renforcement de ses moyens de fonctionnement. »
Rapport de la Commission IA, mars 2024, recommandation 15
La Commission IA propose également de réformer son mandat pour y intégrer un objectif de soutien à l'innovation et à l'expérimentation, et de supprimer les procédures d'autorisation préalable - lourdes et non prévues par le RGPD, qui leur préfère un contrôle ex post - afin notamment de faciliter l'accès aux données de santé. Ces propositions, moins consensuelles, ne concernent pas le domaine du présent rapport, où l'exploitation des données personnelles est déjà encadrée par des dispositions spécifiques protectrices.
En tout état de cause, la protection des libertés et droits fondamentaux passe par le principe de primauté humaine : l'IA peut proposer, mais jamais décider.
III. SE DONNER LES MOYENS
Enfin, mettre l'IA et l'IA générative au service de l'intérêt général impliquera, dans la sphère fiscale et sociale comme ailleurs, de s'en donner les moyens - humains, financiers, techniques et juridiques. Là encore, on se limitera à rappeler six grands enjeux.
A. LA MÉTHODE : SOUPLESSE ET EXPÉRIMENTATION
Les projets comme Llamandement et Foncier innovant à la DGFiP ou 100 % scanning à la douane ont montré l'intérêt d'une démarche fondée sur l'expérimentation : il s'agit de commencer petit » pour apporter la « preuve du concept » (POC), de permettre aux agents volontaires de tester leurs idées, de s'appuyer sur de petites équipes transversales. Il faut aussi savoir accepter l'échec, et c'est évidemment plus facile dans le cas d'une expérimentation qu'avec un grand chantier informatique qui s'étale sur dix ans et dont le coût se chiffre en dizaines ou centaines de millions d'euros : si le POC fonctionne, tant mieux, et si non, ce n'est pas grave.
L'IA générative, par sa simplicité d'utilisation, se prête particulièrement à l'expérimentation. Encore faut-il que cela se fasse dans un cadre sécurisé, notamment s'agissant de la protection des données, ce qui implique d'avoir un accès local aux modèles (et non sur le cloud), et donc de disposer de la puissance de calcul nécessaire. On ne peut que souscrire à la proposition de la Commission IA :
« Lancer un grand mouvement d'expérimentation au sein du service public. Ouvrir dès l'été 2024 une offre de modèle de langage généraliste sur une infrastructure sécurisée afin de laisser tout agent public l'expérimenter dans le cadre de son travail. Assurer la collecte des données d'utilisation pour mieux comprendre les usages. Sécuriser la puissance de calcul nécessaire à l'ouverture généralisée. »
Rapport de la Commission IA, mars 2024, recommandation 9.5
B. LA GOUVERNANCE : VOLONTARISME ET COORDINATION
Pour des administrations cloisonnées et hiérarchisées, faire preuve de souplesse et encourager l'expérimentation demande, paradoxalement, une gouvernance forte et un engagement durable.
La priorité est de renforcer la coordination interministérielle : les administrations ont besoin d'une doctrine, d'un accompagnement, d'outils et d'un accès aux modèles, aux données et à la puissance de calcul. Ce rôle incombe en premier lieu à la direction interministérielle du numérique (Dinum), qui doit être renforcée et confortée dans son rôle de coordination, au-delà des projets qu'elle mène en propre (le chatbot Albert, par exemple). Aujourd'hui, le département Etalab de la Dinum ne compte qu'une trentaine d'agents, dont quatre se consacrent spécifiquement à l'IA.
Le coordinateur national pour l'intelligence artificielle a aussi un rôle à jouer, notamment pour faire le lien entre les besoins (dans le service public) et l'offre de solutions (par les entreprises), mais les faibles moyens dont il dispose - essentiellement lui-même et son adjoint - lui permettent à peine d'assurer son rôle d'animation de la filière et de suivi du volet IA du plan France 2030. La coordination devrait également être renforcée entre acteurs de la sphère fiscale et de la sphère sociale, et au sein de chaque sphère, où une administration chef de file pourrait être désignée. À Bercy, la DGFiP semble tout indiquée.
Le coordinateur national pour l'IA
Créé en 2018 et rattaché à la direction générale des entreprises (DGE), il est chargé de coordonner la stratégie nationale pour l'IA, et notamment de son volet financier, soit 4 milliards d'euros prévus dans le cadre du plan France 2030 pour faire de la France un leader en Europe et dans le monde en matière d'IA.
Depuis 2023, le coordinateur pour l'IA est Guillaume Avrin, docteur en robotique et en neurosciences, précédemment responsable du secteur IA au Laboratoire national et métrologie et d'essais
Enfin, chaque administration ou organisme de sécurité sociale devrait, en interne, se doter d'une gouvernance adaptée. Sans entrer ici dans le détail, on signalera que différents modèles sont possibles, et que l'articulation entre les services en charge de la transformation et de l'expérimentation d'une part (typiquement la DTNum à la DGFiP, ou la mission « Valorisation des données à la douane »), et les services « métiers » et la DSI d'autre part, constitue un enjeu crucial.
C. LES COMPÉTENCES : RECRUTEMENTS POINTUS ET DIFFUSION LARGE
L'enjeu des compétences est double : le recrutement de profils spécialisés d'une part, et l'acculturation et la formation des agents d'autre part.
Le recrutement de data scientists, et surtout de spécialistes de l'IA (ML Ops), constitue un défi, compte tenu des rigidités propres à la fonction publique, en termes de statut comme de rémunération - ce dernier obstacle, moindre en début de carrière et partiellement compensé par l'intérêt des missions, devient plus sensible par la suite, compte tenu de la forte demande dans le secteur privé. L'enjeu est donc tout autant de recruter que de fidéliser. Permettre aux agents d'expérimenter, et surtout d'avoir accès aux outils « standard » du métier, comme désormais GitHub Copilot, l'assistant IA de Microsoft pour les développeurs (cf. supra), est impératif.
Les services de l'État comptent au total un peu plus de 2 000 « experts de la donnée », une catégorie large, dont un tiers se trouvent au sein des services statistiques (Insee, etc.). Les spécialistes de l'IA sont beaucoup plus rares, et disséminés dans différents services. Dans la sphère fiscale et sociale, c'est la DGFiP qui dispose des équipes les plus étoffées. Lors de la présentation du bilan du plan de lutte contre les fraudes fiscales, sociales et douanières, le Premier ministre a annoncé de nouveaux recrutements, notamment dans les équipes chargées du datamining. Si les spécialistes en IA ne devraient représenter qu'une petite partie de ces recrutements, c'est néanmoins une bonne nouvelle.
L'autre aspect de la montée en compétence concerne l'ensemble des agents : un effort de sensibilisation et de formation à l'IA, à ses usages et à ses risques (fuite de données, biais et hallucinations, etc.), doit être mené.
Il a d'ailleurs déjà commencé. L'Urssaf, par exemple, a créé une exposition itinérante pour sensibiliser ses collaborateurs et leur permettre de se familiariser avec les outils et de tester des usages (« bar à prompts », etc).
L'exposition itinérante de l'Urssaf
Cette politique de sensibilisation interne ambitieuse, qui s'appuie aussi sur un accompagnement des projets et des volontaires, la mise à disposition de licences et d'environnements de développement dédiés et sécurisés, doit être saluée. Elle est d'autant plus pertinente que l'IA générative, avec son chat en langage naturel et sans besoin de connaissances spécifiques, offre une facilité d'accès inédite, et même parfois ludique.
D. LE CHOIX DE LA TECHNOLOGIE : QUELS MODÈLES POUR QUELS BESOINS ?
On considère généralement que les progrès de l'IA intervenus au cours des dernières années sont dus à trois facteurs : la sophistication des modèles, certes, mais aussi et surtout la quantité de données disponibles, et plus encore l'explosion de la puissance de calcul. Ces mêmes conditions se retrouvent pour les usages de l'IA dans la sphère fiscale et sociale.
Les modèles peuvent être ouverts (open source) ou fermés (modèles propriétaires), généralistes ou spécialisés, gratuits ou payants, plus ou moins performants, etc. Ici, une approche proportionnée aux cas d'usage s'impose : s'il est évidemment exclu d'utiliser des modèles fermés, dont on ne maîtrise pas les paramètres, pour traiter des données sensibles ou issues de systèmes d'information critiques, de même qu'il est exclu d'entraîner des modèles à partir de données internes sur une infrastructure cloud dont l'administration n'aurait pas la maîtrise, des expérimentations (POC) sur des données anonymisées ou des usages généralistes (traduction, synthèse, génération de code, etc.) peuvent tout à fait s'accommoder de solutions grand public, y compris ChatGPT le cas échéant.
L'essentiel, ici, consiste à définir une doctrine et à mettre en place les garde-fous nécessaires (environnement dédié, etc.). Il n'est évidemment pas question qu'un agent du contrôle fiscal demande à ChatGPT d'analyser pour lui un dossier - en revanche, il pourrait être utile que chacun se rende compte de ce qu'il est possible d'en attendre.
« Ces ingrédients ne dessinent toutefois pas une stratégie, qui devra éviter deux écueils. D'une part le “grand projet IA”, destiné à tout faire, tout remplacer, développé loin des agents, des usagers et de la réalité du service public. D'autre part le “tout ChatGPT”, dans lequel un robot conversationnel universel commercial et étranger deviendrait la seule utilisation de l'IA dans le service public. »
Rapport de la Commission IA, mars 2024
E. L'ACCÈS AUX DONNÉES : L'ENJEU DES ÉCHANGES D'INFORMATIONS
S'agissant de l'accès aux données, à la fois pour entraîner les modèles et pour les utiliser, les administrations fiscales et sociales se trouvent dans une situation particulièrement favorable, et sans équivalent dans le service public : les données dont elles ont besoin sont des données internes, déjà disponibles, et dont l'exploitation est déjà autorisée, et déjà très encadrée. Ce sont aussi des données massives, exhaustives, fiables, homogènes, uniques et gratuites. En théorie, l'accès à des données de qualité et en grandes quantités ne constitue donc pas un problème ici, à la différence d'autres domaines - la santé, par exemple - où il s'agit d'un enjeu majeur.
Encore faut-il pouvoir effectivement et facilement y accéder, pour tester des cas d'usage, entraîner des modèles, puis les utiliser. Le défi à relever n'est pas d'ordre juridique, mais d'ordre technique, et d'ordre « culturel ».
En interne, les données demeurent cloisonnées, et l'accès est compliqué non seulement par le manque d'interconnexion des SI (cf. supra), et par la lourdeur des procédures. Avec la généralisation des datalakes, tels que celui du pôle datamining de la DGFiP ou de la mission « Valorisation des données » de la douane, le pas essentiel a été franchi. Il reste à en ouvrir l'accès, progressivement et sous l'autorité des services en charge, aux porteurs de projets issus des services de terrain.
Le véritable problème reste celui des échanges d'informations entre administrations : ceux-ci sont prévus par une série de protocoles ad hoc signés de façon bilatérale et au cas par cas, ils portent encore sur un nombre limité de traitements de données, et leur mise en oeuvre concrète se heurte à de nombreux obstacles techniques et administratifs. Le législateur a pourtant depuis longtemps mis en place le cadre nécessaire à la généralisation de ces échanges, et ceux-ci faisaient partie des priorités du plan de lutte contre les fraudes annoncé par Gabriel Attal.
« mesure en finalisation / à venir »
À titre d'exemple, sur les 35 mesures du plan de lutte contre les fraudes de 2023, près de la moitié de celles qui n'ont pas encore été mises en oeuvre concernent les échanges d'informations :
- accès de la CNAV au fichier Ficoba ;
- base interministérielle de RIB frauduleux ;
- accès au fichier PNR pour repérer les fraudes à la fausse résidence ;
- « améliorer le partage d'informations entre services de lutte contre les fraudes » ;
- partenariat DGFiP/DGDDI ;
- partenariat DGFiP/Urssaf ;
- coopération CNAM/complémentaires santé.
Les auditions ont permis de confirmer que ces échanges étaient insuffisants, et que même les simples réunions de coordination entre services chargés des mêmes missions dans des administrations similaires n'avaient lieu que très occasionnellement.
F. L'INFRASTRUCTURE DE CALCUL : INVESTISSEMENT ET MUTUALISATION
Enfin, une infrastructure de calcul spécifique - les processeurs graphiques, ou GPU - est nécessaire pour entraîner les modèles comme pour les utiliser. Or la demande mondiale est aujourd'hui largement supérieure à l'offre, sur laquelle la société américaine Nvidia, avec sa puce H100 à 40 000 dollars l'unité, est en situation de quasi-monopole (80 % de part de marché), même si des concurrents émergent. Pour donner un ordre de grandeur, Meta a récemment annoncé l'acquisition de 350 000 puces H100 pour entraîner son prochain modèle, pour un montant estimé à...9 milliards de dollars (avec une importante réduction, donc).
L'État n'a pas de tels moyens. Bien sûr, celui-ci n'a pas besoin d'entraîner ses propres modèles de base, mais il aura besoin d'une puissance de calcul non négligeable pour le fine-tuning, afin de les adapter à ses usages dans le cadre du service public. L'alternative consiste à faire appel à un prestataire privé, en entraînant les modèles et en les déployant sur un cloud comme celui de Microsoft (Azure) ou d'Amazon (AWS). Renoncer à la maîtrise de l'infrastructure, au profit d'un acteur étranger de surcroît, implique cependant des risques importants (fuites de données, etc.), qui sont évidemment inacceptables pour des applications critiques telles que la gestion du système fiscal et social, ou même la seule détection de la fraude. C'est pourquoi la Commission IA fait de ce sujet l'une de ses priorités :
« Faire de la France et de l'Europe un pôle majeur de la puissance de calcul
La dépendance de l'Europe vis-à-vis des États-Unis, déjà forte dans les datacenters, est encore plus criante pour la puissance de calcul. Il n'est pas nécessaire que tous les modèles utilisés en Europe soient entraînés sur son sol. Cependant, un sursaut est indispensable, à la fois pour entraîner des modèles à usages sensibles, et réaliser une partie de l'inférence. [...]
À très court terme, sécuriser l'approvisionnement de l'écosystème français en puissance de calcul privée. Dès 2024, faire une réservation collective d'une puissance de calcul équivalente à 20 000 H100 auprès de fournisseurs de puissance de calcul, y compris hors du territoire national. Louer cette puissance de calcul à prix coûtant aux acteurs de l'écosystème français, en particulier aux start-ups. Si possible dans des délais courts, réaliser cette opération au niveau européen, en particulier avec l'Allemagne. »
Rapport de la Commission IA, mars 2024, recommandation 14
La DGFiP, qui fait partie des administrations ayant commencé à s'équiper, pourrait ici jouer un rôle important, en mutualisant une partie de ses capacités au sein de la sphère fiscale et sociale. L'intérêt est d'autant plus évident que l'entraînement des modèles n'est pas continu.
EXAMEN EN DÉLÉGATION
Réunie le mardi 2 avril 2024, la délégation à la prospective a examiné le rapport de Mme Sylvie Vermeillet et M. Didier Rambaud sur « IA, impôts, prestations sociales et lutte contre la fraude ».
Mme Christine Lavarde, présidente. - Bonsoir à tous. Je serai brève, car je vais immédiatement céder la parole aux rapporteurs Sylvie Vermeillet et Didier Rambaud. Ils vont nous présenter le premier rapport de notre travail collectif sur l'intelligence artificielle (IA) et l'avenir du service public, consacré à IA, impôts, prestations sociales et lutte contre la fraude qui, j'en suis certaine, suscitera l'intérêt. Pour ceux qui ont assisté à l'audition de la direction générale des finances publiques, vous avez découvert un outil d'IA pour la gestion des amendements aux lois de finances d'une puissance exceptionnelle en termes de gain de temps. Cet outil ouvre des perspectives intéressantes que la vice-présidente Sylvie Vermeillet entend, si j'ai bien compris, déployer au sein du Sénat. Nous lui souhaitons réussite dans cette entreprise. Je pense qu'il y a bien d'autres découvertes issues de vos différentes auditions. Nous sommes impatients d'en entendre davantage.
M. Didier Rambaud, rapporteur. - Il me revient d'introduire le sujet, avant que Sylvie Vermeillet ne le développe. Commençons par un rappel historique. Sous l'Ancien Régime, les rois de France confiaient la collecte des taxes et impôts indirects à des financiers, une pratique connue sous le nom de « ferme générale ». Ces fermiers ne pouvaient imaginer que l'intelligence artificielle deviendrait un outil essentiel pour le recouvrement des impôts, le contrôle des prestations sociales ou la lutte contre la fraude. En 2024, l'IA est omniprésente dans notre quotidien, avec ses opportunités, ses inquiétudes, et surtout, son langage.
Comme Nicolas Boileau l'a si bien dit, ce qui se conçoit bien s'énonce clairement. Aussi, pour que notre rapport soit le plus clair possible, permettez-moi de commencer par quelques définitions. L'IA vise l'apprentissage automatique, ou machine learning, par opposition à l'informatique classique. Un programme classique est comme une recette de cuisine, avec des ingrédients et une série d'instructions prédéfinies. L'apprentissage automatique permet à la machine d'apprendre les règles à partir de données d'entraînement. Par exemple, on peut lui apprendre à reconnaître les caractéristiques d'entreprises ayant fraudé la TVA pour mieux détecter cette fraude. Pour les modèles les plus avancés, on parle d'apprentissage profond, ou deep learning, permettant à l'IA de réaliser des tâches plus complexes comme la reconnaissance vocale ou le traitement d'images. Les intelligences artificielles génératives, comme ChatGPT, spécialisées dans le traitement du langage naturel et la génération de contenu (texte, image, code), fonctionnent avec le deep learning.
Actuellement, les administrations fiscales, comme la direction générale des finances publiques (DGFiP) et les douanes, utilisent un système basé sur l'informatique classique. Après avoir auditionné l'Urssaf, la CAF et l'assurance vieillesse, nous faisons le constat que toutes ces caisses de sécurité sociale, responsables de la collecte des cotisations et du versement des prestations, partagent un dénominateur commun. Leur mission principale est de gérer une quantité considérable d'informations, contrairement à d'autres services publics, dont l'activité est marquée par une dimension matérielle et physique, comme l'enseignement, la police sur le terrain ou les soins prodigués aux patients.
Face à ces flux d'informations massifs, l'État a entrepris de transformer ses administrations fiscales par le biais de la révolution numérique. La dématérialisation des procédures et des paiements, la déclaration en ligne, le prélèvement à la source, la déclaration sociale nominative et la facturation électronique ont modifié notre rapport à l'administration, tout comme l'administration elle-même. En quinze ans, la DGFiP a réduit ses effectifs de 30 000 postes, soit 25 %, sans compter les nombreuses fermetures de points d'accueil physiques. La révolution numérique, bien qu'efficace, a engendré quelques difficultés.
L'intelligence artificielle suit un processus similaire en traitant des informations, mais celui-ci est aussi radicalement différent. Pourquoi ? Parce que l'IA, grâce à l'intelligence générative et aux modèles de langage, traite non seulement des chiffres et des données structurées, mais aussi des textes, des mots, des données non structurées et hétérogènes. Cette distinction a des conséquences majeures pour deux raisons. Premièrement, nous pouvons désormais confier à l'IA des tâches liées à tous types de documents : lois, règlements, jurisprudence, doctrine fiscale et sociale, bases douanières, pièces justificatives, échanges d'e-mails et de courriers, comptes rendus de réunion et notes de service. Ces documents sont au coeur du métier, bien plus que les calculs, longtemps délégués aux ordinateurs. Deuxièmement, l'IA, capable de comprendre le langage naturel, peut accomplir une multitude de tâches. L'IA générative peut non seulement améliorer l'efficacité du service public, mais aussi le rendre plus accessible, plus personnalisé et plus proche, en d'autres termes, plus humain. L'IA peut expliquer une démarche complexe de manière simple, rédiger un courrier, traduire un formulaire dans votre langue maternelle.
L'intelligence générative promet par conséquent une révolution numérique avancée, adaptée à nos besoins, comme le souligne la première partie de notre rapport, consacrée à l'expérimentation de l'IA générative.
Tous les acteurs auditionnés reconnaissent son potentiel, mais les expérimentations restent balbutiantes. Les cas d'usage identifiés concernent principalement des tâches administratives génériques ou de bureau, comme les résumés, les analyses, les traductions et la recherche documentaire.
Cependant, des expérimentations spécifiques à certains métiers émergent, comme le projet LLaMandement de la DGFiP, qui sera détaillé par Sylvie Vermeillet. Pour le reste, il s'agit des fameux chatbots, robots conversationnels qui utilisent l'IA générative pour des réponses personnalisées. Albert, le chatbot interministériel, s'entraîne sur le site service-public.fr pour assister les conseillers des maisons France services. La DGFiP développe des chatbots pour aider les agents à répondre aux usagers ou pour des recherches juridiques. Cependant, ces projets ont un défaut commun : ils ajoutent une couche superficielle d'IA à des procédures existantes sans transformation profonde. Albert, par exemple, ne peut pas exécuter des tâches à la place des usagers.
La véritable rupture technologique résidera dans l'intégration de l'IA au coeur des systèmes d'information, avec accès aux dossiers individuels. Bien que nous en soyons encore loin, c'est un objectif à poursuivre. L'enjeu à long terme n'est pas de savoir si l'IA peut remplir un formulaire ou envoyer un justificatif de domicile à votre place, mais plutôt de voir comment l'intégrer efficacement dans nos systèmes. Alors que la simplification est à l'ordre du jour, nos concitoyens s'interrogent sur l'existence d'un formulaire pour fournir des informations déjà détenues par l'administration.
Certes, nous pourrions être perçus comme en retard, mais rappelons que la technologie en question est récente et complexe, soulevant des questions juridiques et philosophiques. L'administration a besoin de temps, et la sagesse que nous cultivons au Sénat nous incite à éviter une précipitation dangereuse. Comparé à nos voisins, Bercy est plutôt en avance. Cependant, nous ne pouvons pas rester immobiles. La délégation a récemment entendu Philippe Aghion et Anne Bouverot, coprésidents de la commission de l'intelligence artificielle, auteurs d'un rapport remis au Président de la République. Le rapport souligne que l'IA est une révolution technologique incontournable, affectant tous les domaines d'activité. Alors que les États-Unis et la Chine l'ont intégrée dans leur stratégie de puissance, nous devons relever le défi pour maîtriser notre avenir. Mes chers collègues, pour y parvenir, il est essentiel de comprendre les limites et les risques de l'intelligence artificielle.
Trois aspects sont particulièrement préoccupants : la protection des données, la fiabilité des réponses de l'IA et leur compréhension. En ce qui concerne nos données, souvent personnelles, leur protection est non négociable. C'est un enjeu de maîtrise technologique, pour ne pas dépendre des entreprises étrangères, et un enjeu juridique. Le cadre juridique est solide, à la fois au niveau européen, avec le Règlement général sur la protection des données (RGPD) et la récente loi sur l'IA (Artificial Intelligence Act), et au niveau national, avec les contrôles de la Commission nationale de l'informatique et des libertés (Cnil) et du Conseil constitutionnel, et les dispositions législatives en matière de secret fiscal et médical. L'enjeu réside dans l'application effective de ce cadre.
Nous avons besoin d'institutions robustes, comme la Cnil, qui soutient déjà les administrations de Bercy et de la sécurité sociale dans leurs projets. La Cnil dispose-t-elle des ressources adéquates pour ses ambitions ? Ne devrions-nous pas renforcer ses pouvoirs avec un mandat plus large et plus de moyens ? La Commission de l'intelligence artificielle le recommande, et nous sommes en accord.
En ce qui concerne la fiabilité des réponses de l'IA, nous sommes également confrontés à un défi majeur. L'intelligence artificielle générative peut parfois présenter des erreurs, des hallucinations. C'est une conséquence directe de sa nature probabiliste. La réponse n'est jamais identique, et dans de rares cas, elle peut être fausse ou absurde. Pour les tâches créatives, comme la génération d'images, ou celles nécessitant une approche statistique, sa nature probabiliste est un atout pour détecter la fraude ou comprendre le langage naturel. Cependant, pour déterminer l'éligibilité à une aide sociale ou calculer un impôt, aucune erreur n'est tolérée. Par conséquent, l'IA sera utile pour certaines opérations, mais pas pour d'autres.
En ce qui concerne la compréhension des réponses données, il faut examiner le fonctionnement de l'intelligence artificielle. Dans le réseau de neurones de l'IA, seules la première couche, l'information d'entrée, et la dernière, la réponse, sont connues de l'utilisateur. Tout ce qui se passe entre les deux est inconnu et incompréhensible pour un humain. Ce sont des fonctions mathématiques abstraites construites par le modèle lors de son entraînement. Par conséquent, non seulement l'IA ne donne jamais la même réponse, mais elle ne peut pas non plus expliquer pourquoi. C'est ainsi qu'une innovation technique devient un défi juridique, car elle contredit trois principes constitutionnels : l'égalité devant la loi, l'accessibilité et l'intelligibilité de la loi, ainsi que le droit à un recours effectif.
En conclusion, il est essentiel de comprendre que l'intelligence artificielle peut proposer, mais ne peut jamais décider. C'est avec cette approche que nous pourrons peut-être développer une intelligence artificielle publique de confiance, souhaitée dans le domaine des finances publiques et de la lutte contre la fraude, un sujet sur lequel ma collègue va s'exprimer plus en détail.
L'intelligence artificielle, bien qu'efficace pour détecter des anomalies, ne doit pas déclencher de contrôles ou de redressements automatiques. L'intervention humaine reste indispensable, et nous devons veiller à ce que cette nécessité perdure.
Mme Sylvie Vermeillet, rapporteure. - Madame la Présidente, mes chers collègues, avant d'aborder la lutte contre la fraude, je souhaite vous présenter le projet d'IA générative le plus avancé à ce jour, qui concerne notre domaine, celui du Parlement, et plus précisément, celui de nos amendements.
Lors de l'examen du projet de loi de finances en séance publique, les services de Bercy sont confrontés à une grande quantité d'informations : 5 400 amendements déposés à l'Assemblée nationale l'an dernier, 3 700 au Sénat, à traiter dans un délai très court. À la commission des finances du Sénat, cette période très courte est surnommée la « nuit de la mort », tant le travail est ardu.
Pour traiter ces amendements, la DGFiP a élaboré un processus innovant en quatre étapes : l'attribution aux bureaux compétents, la recherche d'amendements similaires, le résumé de l'objet et la rédaction de la position du Gouvernement. Habituellement, les amendements sont lus un par un, envoyés au bureau de la direction de la législation fiscale (DLF) compétent à partir d'une recherche dans un tableau Excel. La recherche des similaires est laborieuse, incomplète et source d'erreurs. Combien d'entre nous n'ont pas vu un ministre se rendre compte, en lisant sa fiche de banc, qu'elle aborde un autre sujet ou qu'elle ne tient pas compte d'une rectification ? Enfin, pour la rédaction de la synthèse et de la position, les efforts se concentrent sur les amendements susceptibles d'être adoptés, ce qui signifie que si vous êtes dans l'opposition ou au Sénat, vous n'aurez pas la même attention. L'outil LLaMandement, conçu par la DGFiP, automatise les trois premières étapes. L'attribution de tous les amendements se fait en 15 minutes, au lieu de 6 à 10 heures auparavant. La recherche de similarités prend 10 fois moins de temps et le résumé de l'objet est effectué instantanément par une IA générative, sans perte de qualité. Cela ne bouleverse pas l'organisation de la DGFiP, mais constitue un changement majeur pour les agents concernés. L'intérêt du projet réside dans la démonstration de ce que l'IA générative peut produire avec deux data scientists en stage d'immersion à la DLF et six mois de travail. C'est un outil auquel le Sénat s'intéresse avec prudence, mais aussi avec un grand intérêt. Passons maintenant à la lutte contre la fraude.
Dans le domaine de la détection de la fraude, l'intelligence artificielle est utilisée depuis plusieurs années, son intérêt étant particulièrement évident. Une distinction notable existe entre les administrations de la direction générale des finances publiques (DGFiP) et de la douane, d'un côté, et la sphère sociale de l'autre. La DGFiP, pionnière du data mining, croise les données pour détecter des anomalies en fonction de certains seuils et critères de risque, de manière centralisée par une équipe de 30 personnes, dont 10 data scientists. Le traitement des données génère une liste de contribuables pour le contrôle sur le terrain. Tous les pays de l'OCDE utilisent le data mining, la DGFiP ayant débuté il y a une dizaine d'années. Aujourd'hui, 50 % des contrôles des professionnels et 36 % des contrôles des particuliers proviennent du data mining. L'activité principale de la DGFiP concernant les professionnels, on peut dire que la moitié de la programmation du contrôle fiscal est désormais automatisée. Les gains de productivité, bien que non chiffrables, sont significatifs.
Le data mining a-t-il amélioré la détection de la fraude ? Les résultats du contrôle fiscal sont en hausse, avec plus de 15 milliards mis en recouvrement cette année, mais sur plusieurs années, les résultats restent stables et la part des contrôles donnant lieu à un redressement est constante. Les contrôles issus du data mining représentent la moitié des contrôles, mais seulement 2 milliards de recettes sur les 15 milliards. Le data mining a donc automatisé la programmation, mais pas nécessairement amélioré la détection. L'IA est donc au coeur du sujet, car le data mining n'est pas du machine learning. La base du data mining est de simples croisements de données, de l'informatique classique, mais pas de l'IA. Les indicateurs ne distinguent pas entre les deux, mais le contenu en IA du data mining est limité, expliquant peut-être l'absence d'augmentation massive des résultats. Le data mining avec IA utilise principalement l'apprentissage automatique supervisé, une technique simple, mature depuis 20 ans et largement répandue, utile lorsque l'on sait déjà ce que l'on cherche.
Pour repérer des fraudes complexes ou inconnues, l'apprentissage non supervisé est essentiel, permettant à la machine de trouver les corrélations par elle-même. Cependant, cette technique sophistiquée reste marginale. À la douane, l'administration, dotée de milliards de données sous-valorisées, a adopté le data mining et recruté six data scientists. Malgré ces efforts, ces six personnes demeurent insuffisantes.
En comparaison avec Bercy, la sphère sociale est sur la défensive. Le data mining y est plus récent, moins assumé et sans IA. L'algorithme de scoring de la CAF, au coeur d'une polémique l'an dernier, n'est qu'un croisement basique avec des données de risque prédéfinies. Accusée de cibler les plus pauvres, la CAF soutient que les aides sont destinées aux plus démunis. L'IA a l'avantage d'apprendre à détecter la fraude sans critères a priori, améliorant nettement les résultats. En un an, le montant des fraudes détectées par l'Assurance maladie a bondi de 50 % à 406 millions d'euros, après une stagnation entre 200 et 300 millions d'euros depuis 10 ans. Pour les centres de santé, le montant des fraudes a été multiplié par 10. Les redressements Urssaf ont augmenté de 50 % en un an, atteignant 1,2 milliard d'euros. Même tendance à la CAF et pour l'assurance vieillesse. Ces progrès, obtenus par de simples croisements de données, ont justifié le relèvement des objectifs par le Premier ministre.
Lorsqu'on évoque l'IA en matière de lutte contre la fraude fiscale ou sociale, on parle d'outils simples, loin de la frontière technologique ou du niveau standard dans le secteur privé. Récemment, devant notre délégation, le professeur Raphaël Gaillard a évoqué l'IA pour aider les victimes d'accidents à retrouver la parole ou l'usage de leurs jambes. Il s'agit d'un tout autre registre et des avancées de l'IA des 10 dernières années avec l'apprentissage profond, ou deep learning, et des réseaux de neurones. En matière de lutte contre la fraude, cette technologie n'est pas utilisée, à l'exception de deux initiatives récentes et prometteuses de la DGFiP et de la douane.
Le projet Foncier innovant, piloté par la direction de la transformation numérique de la DGFiP, exploite le deep learning pour identifier des constructions non signalées. Testé sur les piscines, il a révélé 23 000 installations non déclarées dans 9 départements pilotes, générant 10 millions d'euros de recettes supplémentaires pour les communes. Sa généralisation à la métropole est estimée à 5 % du parc privé, soit 43 millions d'euros, démontrant l'efficacité du deep learning.
À la douane, un outil a été conçu pour détecter les stupéfiants dans le fret express et le courrier, un trafic massif échappant aux autorités. Le projet 100 % scanning prévoit de scanner les paquets puis d'analyser les images avec une intelligence artificielle. Bien que le système ne soit pas encore en place, l'algorithme est opérationnel et repère le cannabis et la cocaïne dans 80 % des cas.
Ces deux projets sont prometteurs et pourraient être étendus à d'autres domaines, comme le contrôle des containers dans les ports ou des passagers suspectés d'être des mules. Si l'IA multiplie l'efficacité de la détection de la fraude par 100 ou 1 000, l'administration actuelle ne pourra absorber un tel volume. Ces exemples mettent en lumière le dilemme de l'efficacité. L'IA générative, avec son aptitude à traiter le langage naturel et les données non structurées, pourrait révolutionner la lutte contre la fraude complexe, l'évasion fiscale internationale, le renseignement fiscal et les enquêtes.
J'en viens maintenant à nos recommandations, axées autour de trois priorités.
Premièrement, il est essentiel d'identifier précisément les usages de l'intelligence artificielle en déterminant clairement ce qu'elle peut et ne peut pas accomplir.
Deuxièmement, nos objectifs doivent être clairs : l'IA doit améliorer le service public en facilitant le travail des agents et en offrant un meilleur service aux usagers, plus efficace et humain. Elle doit également permettre des économies, une réalité que nous devons accepter. L'IA automatisera certaines tâches, entraînant la disparition de certains métiers, mais elle en augmentera d'autres, conduisant les agents à se concentrer sur des tâches à plus forte valeur ajoutée, moins répétitives. L'équilibre entre ces deux aspects reste à déterminer. Enfin, l'IA ne doit en aucun cas porter atteinte à nos libertés et droits fondamentaux. C'est l'enjeu majeur de l'AI Act, qui vise à trouver le bon compromis entre protection et innovation. Le texte propose une approche basée sur le niveau de risque, avec des exclusions pour la manipulation du comportement, le crédit social, l'identification biométrique hors impératif de sécurité, et des obligations renforcées pour les modèles de fondation comme ceux d'OpenAI, Google et Mistral AI. La France a approuvé ce texte le mois dernier. Sa mise en oeuvre et son adaptation aux différents domaines seront déterminantes. Il faudra réfléchir à ce que cela signifie pour l'impôt et notre système social.
Troisièmement, pour relever ce défi, nous devons nous doter des moyens humains, techniques, juridiques et financiers nécessaires.
Bien qu'il soit trop tôt pour entrer dans les détails, nous pouvons évoquer six grands enjeux. Premièrement, adopter une méthode basée sur l'expérimentation, commencer petit pour prouver le concept, permettre aux agents volontaires de tester leurs idées, en s'appuyant sur de petites équipes transversales. Deuxièmement, améliorer la coordination. Nous avons rencontré le coordinateur national pour l'IA, Guillaume Avrin, et son adjoint. Ils ont déjà beaucoup à faire pour structurer la filière, car la France a tous les atouts pour devenir un acteur majeur. Cependant, ils ont peu de temps pour la coordination interne. Les administrations auraient grandement besoin d'une doctrine commune, d'un catalogue d'outils, et d'un accès mutualisé à la puissance de calcul. En principe, la direction interministérielle du numérique (Dinum) devrait jouer un rôle clé, mais elle manque de moyens, particulièrement face à l'influence de Bercy. Un chef de file devrait être désigné, et la DGFiP semble être le choix évident. Trois axes d'investissement sont nécessaires : d'abord, renforcer les compétences. Cela implique le recrutement de profils spécialisés, leur rémunération et leur fidélisation, ainsi qu'un effort de sensibilisation et de formation à l'échelle de l'administration. Deuxièmement, accéder à la technologie. Les modèles, qu'ils soient ouverts ou fermés, gratuits ou payants, doivent être adaptés aux usages. Troisièmement, investir dans la puissance de calcul, un enjeu mondial, notamment pour les unités de traitement graphique (GPU), essentielles à l'intelligence artificielle. Quelques administrations ont déjà commencé à s'équiper, ce qui est une avancée positive. Ensuite, l'accès aux données est crucial. Les administrations fiscales et sociales disposent de données internes utiles, déjà disponibles et autorisées à être exploitées. Ces données sont massives, exhaustives, fiables, homogènes, uniques et gratuites. Cependant, le vrai défi réside dans l'échange insuffisant de données entre les administrations. Malgré la levée des obstacles juridiques par le législateur, les échanges restent limités.
Voici quelques pistes pour progresser. Je vous remercie de votre attention. Je tiens également à remercier toute l'équipe de la délégation pour leur accompagnement tout au long de ce débat, des auditions et pour la production de ce rapport. Nous avons demandé à ChatGPT de produire notre rapport, uniquement à partir des données fournies. L'IA a été très créative, produisant toutes les illustrations que vous voyez. Pour le rapport lui-même, le résultat est assez impressionnant. Nous ne nous attarderons pas dessus, mais gardez à l'esprit que ChatGPT peut élaborer un rapport captivant sur cette intelligence artificielle.
Mme Christine Lavarde, présidente. - Je tiens à exprimer ma sincère gratitude à tous les deux pour avoir initié ce cycle de courts rapports, qui, bien que qualifiés de « courts » selon la terminologie de la Cour des comptes, s'étendent sur 50 pages, un format standard pour nos rapports.
Je vous remercie non seulement pour le traitement du sujet abordé, mais aussi pour les précieuses explications techniques sur l'intelligence artificielle et les concepts connexes, qui seront sans doute repris ou cités dans les travaux ultérieurs de la délégation. L'effort déployé sur la forme est également apprécié, je suis convaincue qu'il sera beaucoup plus engageant pour nos collègues. Dès ce matin, des journalistes m'ont d'ailleurs sollicitée pour obtenir une copie du rapport, témoignant de l'intérêt suscité.
Didier Rambaud nous a offert une synthèse éclairante sur le calcul quantique, et Sylvie Vermeillet a évoqué la « nuit de la mort » dans une vidéo produite par la direction de la communication du Sénat, illustrant ce que les humains faisaient avant, et ce qu'ils ne feront peut-être plus grâce à l'intelligence artificielle. Il est essentiel que nous prenions le temps de lire attentivement ces rapports. Ils ont le mérite de définir clairement ce qui est possible et ce qui ne l'est pas, à travers des exemples concrets qui parleront à tous. Lorsque nous discuterons de la santé ou d'autres sujets, nous aborderons peut-être des aspects plus techniques, mais ici, tout le monde est concerné, que ce soit par le paiement des impôts ou la perception de prestations sociales. Ces rapports montrent ce que l'on peut accomplir et comment simplifier la vie des agents.
Cependant, il est important de noter que l'intelligence artificielle, bien qu'efficace, peut créer un sentiment de mal-être au travail. Un service, dont je tairai le nom, a confié lors d'une audition que l'intelligence artificielle traite désormais tous les dossiers faciles, laissant aux agents uniquement les dossiers difficiles à gérer. Il sera nécessaire d'ajouter de l'empathie. Lorsqu'on évoque la transformation des métiers, l'humain se retrouvera dédié aux cas les plus complexes. Cela suscite sans doute des interrogations ou des commentaires parmi vous.
Mme Amel Gacquerre. - Je tiens à remercier sincèrement les auteurs de ce premier rapport, prélude à une série d'analyses approfondies. Il établit des fondations solides qui permettront d'éviter des redondances dans les travaux ultérieurs. Cela nous incitera à explorer davantage le coeur des sujets, avec une approche plus directe. J'apprécie l'effort déployé qui servira de point de départ pour les recherches à venir.
La notion de pénibilité au travail a retenu mon attention. C'est un aspect souvent négligé et l'exemple que vous avez cité illustre parfaitement son importance. Cela soulève des questions essentielles sur nos relations au travail, un sujet qui mérite une réflexion plus approfondie, peut-être dans un cadre différent.
Deux points abordés dans votre rapport m'ont particulièrement marquée : la compétence en intelligence artificielle et le manque d'échange d'informations entre les administrations. Concernant la compétence, je m'interroge sur la manière dont elle est traitée au sein des administrations : par des recrutements internes ou par des collaborations extérieures ?
En ce qui concerne l'échange d'informations, il est évident que nos administrations travaillent souvent en silo. C'est un défi majeur que nous devons surmonter. J'aimerais savoir si des efforts sont déployés pour améliorer la situation. L'efficacité, dont nous parlions, passe avant tout par la cessation du travail en silo. Un grand merci pour votre travail.
M. Jean-Raymond Hugonet. - J'ai deux questions précises. Premièrement, j'ai noté la diminution de 30 000 postes à la DGFiP au cours des 15 dernières années, soit 2 000 emplois par an, est-ce bien cela ? Deuxièmement, vous avez évoqué le traitement des amendements après leur dépôt. J'aimerais savoir si vous avez étudié l'impact de l'intelligence artificielle sur ce processus, particulièrement dans le contexte où certains collègues, en application du droit sacré d'amendement des parlementaires, se voient confrontés à un nombre excessif d'amendements qui n'apportent pas une contribution significative. Avez-vous eu l'occasion d'expertiser ce phénomène ?
Mme Nadège Havet. - Je vous félicite pour le travail accompli. J'apprécie que vous ayez clarifié les différents aspects de l'intelligence artificielle. Ma question concerne le domaine social. Avez-vous ressenti une volonté de progresser ? Vos propos mettent en évidence les défis liés au traitement et à la corrélation des données. Cependant, existe-t-il une réelle intention de surmonter ces obstacles, ou sommes-nous plutôt réticents à avancer ?
M. Stéphane Sautarel. - Merci pour cette présentation éclairante. Mes interrogations se concentrent sur les aspects humains de l'intelligence artificielle, en particulier les freins culturels qui entravent son adoption. Je m'intéresse aussi à la qualité de vie au travail et à l'impact de l'IA sur les tâches quotidiennes. Comme notre présidente l'a souligné, l'IA pourrait laisser aux employés les tâches les plus complexes, ce qui pourrait générer des résistances. De plus, je m'interroge sur la disponibilité des ressources humaines nécessaires et la capacité du secteur public à les rémunérer. Dans le système actuel, sommes-nous en mesure de relever ces défis institutionnels ? Avez-vous identifié des limites liées à notre cadre d'action actuel ?
M. Didier Rambaud, rapporteur. - Je ressens une certaine frustration sur ce travail car le calendrier était particulièrement serré. Il s'agit donc d'une mise à plat, d'un premier jet. Il y a six mois, l'intelligence artificielle était encore un concept flou pour moi. Cependant, j'étais conscient qu'il s'agissait d'une révolution majeure, la plus radicale depuis l'invention de l'imprimerie par Gutenberg, et que nos vies seraient désormais rythmées par des algorithmes. En tant que membre de la commission des finances, le sujet de la lutte contre la fraude m'a particulièrement intéressé, un enjeu auquel le Sénat porte une attention particulière depuis plusieurs années. C'est pour cette raison que je me suis lancé dans cette aventure. Cependant, je reconnais avoir encore besoin d'affiner mes connaissances, notamment sur le plan technique.
Mme Sylvie Vermeillet, rapporteure. - Il est indéniable que le logiciel de la DGFiP, qui traite 3 700 amendements au projet de loi de finances en 15 minutes, suscite l'intérêt du Sénat. Ce logiciel, en open source, a clairement un intérêt pour la réduction de la pénibilité. Cependant, le mal-être au travail est lié à la culture des administrations. La DGFiP et les douanes, engagées dans l'intelligence artificielle, cherchent des résultats, contrairement à la sphère sociale, qui reste prudente, je le confirme à Nadège Havet. Les arguments avancés sont la sensibilité et la protection des données.
Pourtant, les impôts sont également des données sensibles. La DGFiP, qui traite ces données, a vu deux ingénieurs prendre l'initiative de travailler sur les amendements grâce à une expertise acquise lors d'un stage de six mois. Il y a une vraie motivation et un désir de résultats. Les administrations de la sphère sociale, bien qu'elles utilisent des chatbots pour répondre aux questions des usagers, hésitent à aller plus loin dans le traitement des données. On perçoit une réticence, un manque de volonté, illustrant deux mondes distincts.
L'absence d'échange de données entre les administrations est évidente, témoignant d'une divergence culturelle et d'une approche différente de l'intelligence artificielle. Dans le contexte social, on évoque le risque de mal-être engendré par l'IA. Cependant, l'approche doit être prudente, comme nous l'avons souligné. La protection des données est un enjeu majeur, un point sur lequel la DGFiP est claire. Lorsqu'une sélection de données est effectuée, la machine apprend à sélectionner, mais c'est toujours l'humain qui a le dernier mot sur les dossiers à contrôler. La machine propose, mais c'est l'humain qui décide. Les dossiers les plus complexes restent entre leurs mains, et les agents semblent satisfaits de cette situation.
Les efforts de recrutement interne et les formations restent à développer, un point souligné lors de l'audition de la commission de l'IA. Aujourd'hui, on estime qu'il y a environ 2 000 experts en données en France, dont un tiers sont des statisticiens, ce qui ne répond pas à nos besoins actuels. Nous manquons d'experts en IA. Nous avons rencontré deux experts à la DGFiP qui ont travaillé sur le projet LLaMandement, et bien que nous en ayons également rencontré au sein des douanes, ils sont extrêmement rares. Le plan de lutte contre la fraude de 2023 prévoit 35 mesures, dont la moitié n'est pas mise en oeuvre. Par exemple, la base interministérielle des RIB frauduleux n'est pas partagée entre les administrations, ce qui est surprenant. Les partages d'informations entre la DGFiP et les douanes, entre la DGFiP et l'Urssaf, entre la Cnam et les complémentaires de santé, ne se font pas. C'est un problème majeur.
Lorsqu'on interroge les administrations sur leur collaboration, la réponse est souvent évasive. La Dinum, bien qu'ayant pour mission de faciliter le dialogue, semble ne pas jouer pleinement son rôle. De même, la DGFiP, bien qu'affirmant sa disponibilité, ne semble pas suffisamment engagée dans la communication inter-administrations.
La sphère sociale, quant à elle, se concentre davantage sur les chatbots. Les douanes et la DGFiP, dotées d'outils plus avancés, font figure de pionniers, notamment grâce à un outil interne développé par les douanes pour scanner les colis. Conçu avec ingéniosité, cet outil est d'une efficacité remarquable. Ces équipes sont ainsi à la pointe en Europe, grâce à leur volonté d'innover. Ces administrations méritent notre soutien. Il est également essentiel d'encourager la sphère sociale à progresser, car malgré les outils limités dont elle dispose, des avancées significatives ont été réalisées.
Mme Christine Lavarde, présidente. - Je tiens aussi à souligner l'évolution rapide des techniques de la douane, observée lors d'une visite avec la commission des finances. Il y a quatre ou cinq ans, la détection des envois illégaux se basait sur l'origine des avions. Par exemple, pour la recherche de drogue, l'attention se portait systématiquement sur les enveloppes provenant des Pays-Bas. L'expéditeur et le format de l'enveloppe étaient également pris en compte. Cependant, ces méthodes reposaient essentiellement sur des statistiques. Aujourd'hui, en quelques mois ou années, nous avons vu l'émergence d'un traitement beaucoup plus sophistiqué, qui dépasse désormais les capacités humaines.
Mme Sylvie Vermeillet, rapporteure. - Je souhaite répondre à Jean-Raymond Hugonet sur la question des amendements. Il est exact que cette question relève de ma vice-présidence. Le président Larcher m'a chargée de travailler sur cette problématique. En Italie, par exemple, un député a déposé 23 millions d'amendements sur un seul texte. Nous souhaitons éviter un tel scénario. Dans le cadre de la réflexion sur la modernisation du travail parlementaire, nous explorons l'utilisation de l'intelligence artificielle pour gérer les amendements. Le système pourrait trier et analyser les amendements, identifier les doublons, et préparer des fiches. Il ne permettrait pas d'entraver le dépôt d'amendements, mais aiderait à les gérer. Nous manquons d'outils juridiques, mais une évolution de notre règlement est envisagée. L'IA pourrait, par exemple, éviter le dépôt de millions d'amendements ne différant que par un chiffre. Nous devons anticiper et préparer une réglementation adéquate. J'ai récemment rencontré une députée italienne pour comprendre leur expérience. Ils ont pris de l'avance sur nous en matière d'IA. Nous pouvons donc observer leurs actions et les problèmes qu'ils pourraient rencontrer.
Un autre aspect prometteur de l'IA concerne l'amélioration des études d'impact et de l'évaluation des politiques publiques. Lorsqu'un projet de loi est soumis, une étude d'impact doit l'accompagner. L'IA pourrait améliorer l'évaluation de ces études, souvent jugées insuffisamment documentées. Lors d'une rencontre avec Yann Le Cun, directeur de l'IA de Meta, je lui ai posé la question : l'IA va-t-elle changer la prise de décision politique ? Sa réponse a été affirmative. L'intelligence artificielle pourrait nous aider à partager et harmoniser les données, en particulier lorsqu'elles sont accessibles en open source.
Ainsi, si nous partagions une évaluation commune des coûts, cela pourrait faciliter un accord sur la priorisation des politiques. Nous pourrions alors nous concentrer sur ce que nous souhaitons réaliser en premier, où nous voulons agir, sans nous préoccuper excessivement des coûts. L'IA promet des avancées significatives pour nos travaux, notamment au Sénat, bien qu'elle puisse sembler effrayante en raison des bouleversements qu'elle pourrait entraîner.
Mme Christine Lavarde, présidente. - Merci pour vos réponses. Je soumets à présent au vote l'adoption du rapport.
La délégation adopte, à l'unanimité, le rapport et en autorise la publication.
LISTE DES PERSONNES ENTENDUES
AUDITIONS PUBLIQUES DE LA DÉLÉGATION À LA PROSPECTIVE
· Gilles Babinet, co-président du Conseil national du numérique (13 décembre 2023)
· Philippe Aghion, économiste, professeur au Collège de France, co-président de la Commission de l'intelligence artificielle (26 mars 2024)
· Anne Bouverot, présidente du conseil d'administration de l'École normale supérieure, co-présidente de la Commission de l'intelligence artificielle (26 mars 2024)
AUDITIONS DES RAPPORTEURS
· Caisse nationale des allocations familiales (Cnaf)
Nicolas Grivel, directeur général
Anna Morvan, chargée des relations institutionnelles
· Caisse nationale d'assurance vieillesse (Cnav)
Véronique Puche, directrice des systèmes d'information
· Direction générale des douanes et droits indirects (DGDDI)
Pascal Lefèvre, délégué à la stratégie
Gowtam Jinnuri, pilote du laboratoire d'innovation de la douane
· Direction générale des finances publiques (DGFiP)
Esther Mac Namara, déléguée à la transformation numérique (DTNum)
Thomas Binder, responsable de l'IA à la DTNum
Joseph Gesnouin, senior data scientist à la DTNum
Yannis Tannier, senior data scientist à la DTNum
Carole Maudet, sous-directrice du contrôle fiscal, du pilotage et de l'expertise juridique
Gilles Clabecq, chef du bureau Programmation des contrôles et analyse des données
Isabelle Oudet-Giamarchi, sous-directrice des missions foncières et de la fiscalité du patrimoine
· Urssaf Caisse nationale
Sophie Patout, directrice par intérim
Carole Leclerc, directrice de l'innovation et du digital
DÉPLACEMENT À CANNES DU 8 FÉVRIER 2024
· Échanges à l'occasion du World AI Cannes Festival
Yann Le Cun, Chief AI Scientist de Meta, professeur à New York University, prix Turing 2018
Patrick Martin, président du Medef
Guillaume Avrin, coordinateur de la stratégie nationale pour l'IA